
Failure detection
In distributed system, it requires at least two independent sources of information to mark a server dowm. One server is not enough. (It’s not enough to simply say because your node can’t contact another node that the other node is down. It’s quite possible that your node is broken and the other node is fine.)
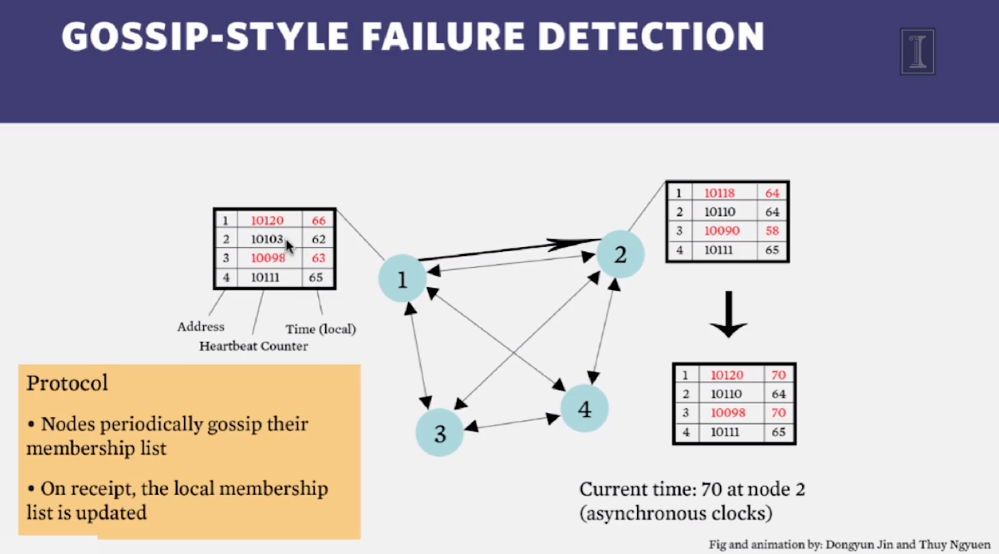
Gossip protocol 【1】
Gossip protocol is a decentralized failure detection method.
- Each node maintains a node membership list, which contains member IDs and heartbeat counters.
- Each node periodically increments its heartbeat counter.
- Each node periodically sends heartbeats to a set of random nodes, which in turn propagate to another set of nodes.
- Once nodes receive heartbeats, membership list is updated to the latest info.
- If the heartbeat has not increased for more than predefined periods, the member is considered as offline.
Handle temporary failures
When the node is down, in strict quorum, read and write operations may be blocked. We can use sloppy quorum to improve availability. the system chooses the first W healthy servers for writes and first R healthy server for reads on the hash ring.
hinted handoff: If a server is down, another server will process requests temporarily. When the down server is up, changes will be pushed back to achieve data consistency.
Handle permanent failures
Anti-entropy