
Introduction
Good morning/afternoon
I’m Chris, I have 1 year experience as a software developer. I have experience in building microservice applications with JavaEE, Spring Boot or Spring MVC, gRPC. For testing: I farmiliar with Junit, Mockito. For databases: MySQL, Oracle DB, cassandra, MongoDB. For Cloud services, I’ve hands-on experience with AWS IAM, S3, EC2, RDS, GCP.
Fiserv is a fintech company, the team I was working for is issuer solution team, we are responsible for the credit/debit card business for several banks and credit unions.
Let me briefly introduce the high level architecture so you can have a better understanding on the points I listed there. We have a ODS main frame which is the core microservices stores and manipulate client data directly. Our services are built on top of the main frame and use restful api through IBM message queue to interact with main frame. The main business logic are implemented in our services. When I was joined, the team was migrating the services from soap to rest, and almost at the end. We have aournd 100 microservices in total, I took over one e-customer microservices from one of the college we finished the whole migration within first two months.
After that, since some of the microservices has many middle component calls, like call main frame to get client credentials like bankId, systemId, etc. Then validate the call from the customer, commit the transactions, reconciliation the results, write memo logs in mainframe, send notifications etc, the logs shows the bottle neck is the client credential validation part, generally it take 70% of the total transaction time. Most of oncall issues are casued by the IBM message queue timeout from the main frame.
To reduce the load of mainframe, and get a quick response time. we built kafka & redis to work as a cache layer between the our microservices and the mainframe, the kafka will batch load the customers configurations ahead every day for those customers paid on this feature and store it to the redis. So each time, every call was made to redis first instead of hit the mainframe. So it lighten the traffic load to the main frame and recude 73% of the average response time for our services.
Daily routine & Agile
We hold daily standard meetings at 9 am, and after that we may have some one-on-one meetings with coworkers or with the external team in the afternoon. At other times, I am working on my own tasks, like coding, write docs, or do some research and code review. For other meetings, we work in Agile, we have sprint planning meeting every two weeks and backlog refinement meeting before planning meeting.
Workflow
For local, write code, pass the code style check, meet 100% code coverage, push to your branch, trigger the build and verify on Jenkins.
Once merged to master, will trigger the following:
1. Build and Verify: code analysis, execute unit tests, build project artifact.
2. Scan: security scan on code using Fority, the vuneralbilities are scanned here.
3. Release: release the artifact to the Sonatype Nexus maven central
4. Deploy: auto-deployed and configured to the DEMO environment using rundeck job
5. Regression: start regression tests on DEMO
6. QA: deployed to QA and do the QA regression
Introduction
Good morning/afternoon/evening/night I’m Chris. I have 6 years experience as a full stack/Java developer
I have experienced in building applications using Java, Spring MVC, JDBC, and Hibernate. I’ve also built microservices using Spring Boot, Eureka, and the Feign Client. For testing, I am familiar with Junit, Mockito, JaCoCo, and Selenium. I have experience with MySQL and MongoDB for databases. As the Cloud services, I’ve had hands-on experience with AWS S3, RDS, EC2, Cloud9. Also, I am familiar with frontend like React or Angular
I currently work for Bolt, You can think of it as a platform that allows merchants to sell their products online. Customers can use Bolt to make payments and track their orders.
My team is responsible for order management and my role is build and maintain the order tracking related microservice.
Responsibilities
currently, I am working for Bolt, It provides a simple way for merchant customers to checkout and make payments. You can think of it as a platform that allows merchants to sell their products online. Customers can use Bolt to make payments and track their orders.
My team and I are responsible for order management. I was involved in developing and maintaining the order tracking related microservices, including order tracking and notification microservice. Beside these, I am also responsible for building the order tracking page using Angular. During the development, I used Factory design pattern to decoupled the app and provide an uniformed interface to handle the order tracking data provided by different carriers Apis.
Structure of the application
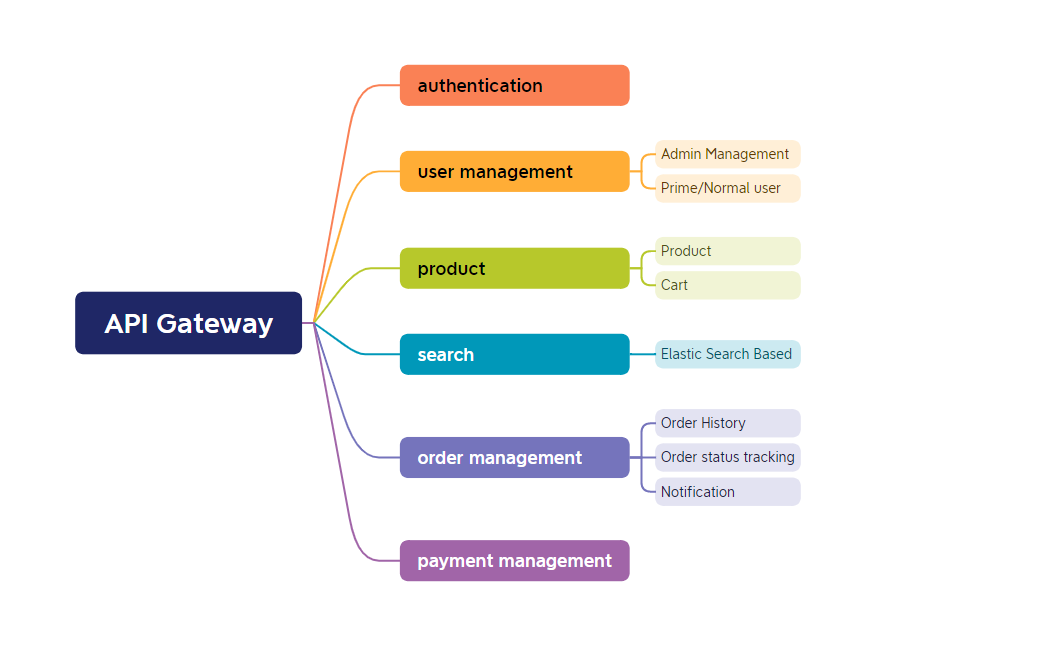
The application is built using microservices architecture. The entrance is the API gateway.
It can divided to several composite serives, including authentication, user management (admin management, user service like prime users), product (product, cart), search (based on Elastic Search),order management (order history, order status tracking, notification), and payment management.
Improve the performance
I use executor service to fetch the order tracking data from different carriers Apis Asynchronously. Also, I used Parallel Streams to handle the data, processing the data in parallel to improve the performance.
Security
For backend, I used Spring Security with JWT to secure the application. for frontend, I used React route guard to protect the routes, also use Interceptor to add the token to the request header.
Also, since we are using AWS, all other microservices are deployed in the VPC, and we use the security group to control the traffic.
Difficult project?
In my recent project at Bolt, I am responsible for order tracking related microservices, when Seasonal offers come, like flash sales, sometimes customers report that they can not see their status after placing the order, this is a damage to the user experience.
To address this problem, I debugged the logs. I found that when we send many requests to external carrier Apis in a short time (like above 200), some of the requests were blocked or got responses around 3-5s, generally it will respond within 1s. After searching, this may be due to their Apis protection mechanism.
To solve this problem, I did thorough research and analyzed potential approaches. I considered solutions like timeout and showing some error messages, but this approach still degrades the user experience.
I also looked at how other organizations were handling similar challenges. I found that Async processing using message queue and the retry mechanism were also a good solution here to deal with it. When the carrier service responds slowly or the requests are blocked, instead of using timeout, we can queue up the request for later processing and show on frontend due to the line busy, please wait for 5-10s, and this is also good for load balancing. When processing requests in a queue, if still no response, we will resend the request.
I discussed with other team members to gather some opinions. To validate this I set up a simplified service that demonstrated how queuing requests can improve the application resilience. After that I solved this problem by using kafka.
From then, We rarely received feebacks about that and it improved the user experience.
Difficult team members (conflict / diff opinion)
I haven’t experienced working with difficult team members but sometimes we hold different opinions about things. In my recent project at Bolt, there was a time I had a difference of opinion with one of my colleagues over the choice of a message broker for our order tracking service.
Initially, I proposed using AWS (SQS) because it seemed like a convenient option given our existing infrastructure on AWS. However, my colleague suggested using Kafka instead.
To address this, I scheduled a one-on-one meeting with him to discuss our viewpoints. During the meeting, I explained why I preferred AWS SQS, emphasizing its compatibility with our current cloud services, like RDS and S3. I argued that even using kafka, we still need to deploy it somewhere. My colleague, on the other hand, was concerned about the potential risk of vendor lock-in. He made a valid point about the potential risks of relying solely on AWS, especially if some day aws goes down. He believed that using Kafka offered more flexibility for future migrations, such as using GCP.
Considering things in the long-term such as potential future migrations to GCP, became a key takeaway from this experience. I also learned to make decisions not only based on project requirements but also with a forward-thinking mindset.
Instead of being stubborn about my viewpoint, I chose to use kafka which efficiently handled the messages and enhanced the overall performance of our application.
Deadline Problem (Mistake, slove, learned)?
This thing rarely happens to me. But in my recent project at Bolt, there was a time I almost missed the deadline, I had a ticket to fix a critical bug in order tracking service, and while I was in the middle of debugging, I met a roadblock, something wrong with the Api of my service. Fortunately we have been paying close attention to the logs, this helps a lot to narrow down the scope. To figure out what happened, I debugged the logs of the service carefully to make sure other functions in my services worked fine and finally found that the order history service (which another coworker was responsible for) crashed unexpectedly, I could not get the result I wanted. At that point, I realized that the downtime could significantly delay my progress.
So, I reported the situation to my manager. At the same time, I reached out to the coworker responsible for that service. I explained the urgency of the situation, and we set up a meeting and estimated the recovery time together. In the end, my manager rescheduled the deadline for my ticket.
Luckily, the server recovered the next day, there was no significant impact on business, and I was able to complete the ticket on time.
In this incident, What I took away was the importance of good communication and logs. A good log can help us narrow down the scope of the problem quickly. Keeping everyone in the loop, collaborating with my teammate to estimate the recovery time and discuss the solutions also contributes a lot.
Daily routine
We hold daily standard meetings at 10 am, and after that we may have some one-on-one meetings with coworkers or with the external team in the afternoon. At other times, I am working on my own tasks, like coding, write docs, or do some research and code review. Also there will be the weekly meeting on Thursday afternoon.
Agile (sprint, planning, review, retrospective)
We work in Agile, we have a sprint every two weeks and we release a new version every two sprint. Generally I got 1-4 tickets per sprint depending on the sprint size. We hold planning meetings ahead of each sprint and review meetings at the end of each sprint. After each quarter around three months, we have retrospective meeting to discuss the following sprints and the goals for the next quarter.
workflow test or deploy
I am responsible for unit tests, and I will run the test to achieve 90% code coverage. For other tests like integration tests or API tests, we have a CI/CD pipeline, which will run other tests automatically (this is provided by the QA team). After making sure the unit test passed, I will commit the code to my branch (it will trigger the automation tests, this is handled by the devops team, we use Jenkins, Docker, AWS EKS for the CI/CD pipeline) After passing the test, I will create a pull request. Then I will ask my team members to review my code and merge the code to the master branch.
After several commits, we will release the new version to the production environment.
multitask
When I had several features to implement and deploy within a short time, while handling an urgent issue in the production environment and coordinating with my coworkers to discuss business requirements.
The key is to prioritize the tasks.
I will break down each task into smaller, manageable pieces. This makes it easier to focus on one sub-task at a time. For instance, I will divide feature implementation into smaller development and testing phases and prioritize them based on deadlines and dependencies.
To deal with production issues, I ensure that I address the most critical problem and communicate with team effectively.
By gradually working on that, I’ve found that I can handle multiple tasks and finish them with high quality.
learn new tech
For frontend, I am initially using HTML and CSS, JSTL stuff (the traditional webpage). At Bolt, we use Angular for frontend, so this is an exciting opportunity for me to learn a new frontend tech.
To get familiar quickly, I began with official online tutorials and courses to know the basic knowledge.
However, when I practice in a simple project. It is really easy to be confused by the some concepts like two way binding. Beside the tutorials, I also relied on the community and online forums to seek other peoples for helps. It was a steep learning curve.
After that, I summarized the key concepts and the basic structure of Angular. By applying Routers and Router Guard, create reusable components, and use services to handle the api calls, I successfully completed the order tracking page using Angular.
team size, location
My company is located in San Francisco, I am working remotely. My team has 9 people, 3 full stack, 3 backend, 2 testing and 1 devops. Shi(Ricky) Yan, Brennan, Paul is the team lead
Gain experience while studying
I graduated this year. My colleague has the policy to allow us to work while taking the degree. My career goal is to become a software engineer, and I realized that many of the courses I was taking in school were outdated or not directly relevant to the industry. So, I decided to work while completing my degree.
why seek new job?
Currently my project is about to end, and I am looking for a new opportunity to further develop my skills and experience. I’m eager to take on new challenges and work in a different environment.
Global delivery & Difficulties
Yes, I have, previously we needed to have weekly meetings with offshore teams in China at night, to bridge the gap between teams, ensuring everyone was on the same page. The important thing is to communicate effectively.
Working with offshore teams can be challenging. The time difference can make it difficult to communicate effectively. Also, the cultural differences can lead to misunderstandings.
Salary expectation
I am not authorized to discuss the rate, and tell the vendor to contact your employer for that