
leetcode 剑指 offer
318. Maximum Product of Word Lengths
167. Two Sum II - Input Array Is Sorted
209. Minimum Size Subarray Sum
713. Subarray Product Less Than K
304. Range Sum Query 2D - Immutable
3. Longest Substring Without Repeating Characters
19. Remove Nth Node From End of List
160. Intersection of Two Linked Lists
430. Flatten a Multilevel Doubly Linked List
708. Insert into a Sorted Circular Linked List
380. Insert Delete GetRandom O(1)
953. Verifying an Alien Dictionary
150. Evaluate Reverse Polish Notation
84. Largest Rectangle in Histogram
919. Complete Binary Tree Inserter
199. Binary Tree Right Side View
297. Serialize and Deserialize Binary Tree
demo
297. Serialize and Deserialize Binary Tree
Solution :
TC : O(1)
SC : O(1)
algorithm
29. Divide Two Integers
Given two integers
dividend and divisor, divide two integers without using multiplication, division, and mod operator.
The integer division should truncate toward zero, which means losing its fractional part. For example, 8.345 would be truncated to 8, and -2.7335 would be truncated to -2.
Return the quotient after dividing dividend by divisor.
Note: Assume we are dealing with an environment that could only store integers within the 32-bit signed integer range: [−231, 231 − 1]. For this problem, if the quotient is strictly greater than 231 - 1, then return 231 - 1, and if the quotient is strictly less than -231, then return -231.
Example 1:
Input: dividend = 10, divisor = 3
Output: 3
Explanation: 10/3 = 3.33333 which is truncated to 3.
Example 2:
Input: dividend = 7, divisor = -3
Output: -2
Explanation: 7/-3 = -2.33333 which is truncated to -2.
Constraints:
-231 <= dividend, divisor <= 231 - 1divisor != 0
solution : use bit operation to solve this problem 利用位运算实现除法

class Solution {
public int divide(int a, int b) {
// corner case int overflow (此时会出现int溢出的情况)
if (a == Integer.MIN_VALUE && b == -1) {
return Integer.MAX_VALUE;
}
// no need to calculate
if (a == 0 || b == 1) {
return a;
} else if (b == -1) {
return -a;
}
// judge the result
boolean neg = false;
if ((a > 0 && b < 0) || (a < 0 && b > 0)) {
neg = true;
}
// since use positive number may cause int overflow, we use the negative number instead.
int num = 0;
int res = -Math.abs(a);
b = -Math.abs(b);
int shift = getMaxShift(res, b);
while (res <= b) {
while (res > (b << shift)) {
shift--;
}
num += (1 << shift);
res -= (b << shift);
}
return neg == false ? num : -num;
}
private int getMaxShift(int res, int b) {
int shift = 0;
while (res <= b) {
res >>= 1;
shift++;
}
return shift - 1;
}
}
TC : O(1) --> Max 32 bit
SC : O(1)
67. Add Binary
(new Method: StringBuilder.insert(index, value))
Given two binary strings a and b, return their sum as a binary string.
Example 1:
Input: a = "11", b = "1"
Output: "100"
Example 2:
Input: a = "1010", b = "1011"
Output: "10101"
Constraints:
1 <= a.length, b.length <= 104aandbconsist only of'0'or'1'characters.- Each string does not contain leading zeros except for the zero itself.
solution1 : it is like the add two linked list, use StringBuilder to save the result
class Solution {
public String addBinary(String a, String b) {
StringBuilder sb = new StringBuilder();
int i = a.length() - 1;
int j = b.length() - 1;
int carry = 0;
while (i >= 0 || j >= 0) {
int num = 0;
if (i >= 0) {
num += (a.charAt(i--) - 48);
}
if (j >= 0) {
num += (b.charAt(j--) - 48);
}
num += carry;
carry = num / 2;
num %= 2;
// use inset here we do not need to reverse the string
sb.insert(0, (char)(num + 48));
}
if (carry == 1) {
sb.insert(0, '1');
}
// if use sb.append, we need to reverse
// return sb.reverse().toString();
return sb.toString();
}
}
TC : O(n) --> n is the max length of a or b
SC : O(1) extra space
solution2 : use bit operation to do this
TODO
338. Counting Bits
Given an integer n, return an array ans of length n + 1 such that for each i (0 <= i <= n), ans[i] is the number of 1's in the binary representation of i.
Example 1:
Input: n = 2 Output: [0,1,1] Explanation: 0 --> 0 1 --> 1 2 --> 10
Example 2:
Input: n = 5 Output: [0,1,1,2,1,2] Explanation: 0 --> 0 1 --> 1 2 --> 10 3 --> 11 4 --> 100 5 --> 101
Constraints:
0 <= n <= 105
Follow up:
- It is very easy to come up with a solution with a runtime of
O(n log n). Can you do it in linear timeO(n)and possibly in a single pass? - Can you do it without using any built-in function (i.e., like
__builtin_popcountin C++)?
solution1 : Brian Kernighan x=x & (x−1) to set last 1 to 0
Repeat until X == 0
class Solution {
public int[] countBits(int n) {
int[] bits = new int[n + 1];
for (int i = 0; i <= n; i++) {
bits[i] = countOnes(i);
}
return bits;
}
public int countOnes(int x) {
int ones = 0;
while (x > 0) {
x &= (x - 1);
ones++;
}
return ones;
}
}
TC : O(nlogn) --> n numbers/ each logn to traverse
SC : O(1)
solution2 : Dynamic programming
y is 2^n when y & (y - 1) = 0
bits[i] = bits[i - highBit] + 1;
class Solution {
public int[] countBits(int n) {
int[] bits = new int[n + 1];
int highBit = 0;
for (int i = 1; i <= n; i++) {
if ((i & (i - 1)) == 0) {
highBit = i;
}
bits[i] = bits[i - highBit] + 1;
}
return bits;
}
}
TC : O(n) --> n numbers/ each O(1)
SC : O(1)
137. Single Number II
Given an integer array nums where every element appears three times except for one, which appears exactly once. Find the single element and return it.
You must implement a solution with a linear runtime complexity and use only constant extra space.
Example 1:
Input: nums = [2,2,3,2] Output: 3
Example 2:
Input: nums = [0,1,0,1,0,1,99] Output: 99
Constraints:
1 <= nums.length <= 3 * 104-231 <= nums[i] <= 231 - 1- Each element in
numsappears exactly three times except for one element which appears once.
Solution1: use hashmap with SC: O(nlogn)
Solution2: use bit operation to solve this problem 利用位运算实现除法
/*
Any bit of the sum of three same number %3 == 0. So we can find for bit i, if the X % 3 != 0, that's the bit of the number we want.
*/
class Solution {
public int singleNumber(int[] nums) {
int ans = 0;
for (int i = 0; i < 32; ++i) {
int total = 0;
for (int num: nums) {
total += ((num >> i) & 1);
}
if (total % 3 != 0) {
ans |= (1 << i);
}
}
return ans;
}
}
TC : O(n * logC) -->C Max 32 bit
SC : O(1)
318. Maximum Product of Word Lengths
Given a string array words, return the maximum value of length(word[i]) * length(word[j]) where the two words do not share common letters. If no such two words exist, return 0.
Example 1:
Input: words = ["abcw","baz","foo","bar","xtfn","abcdef"] Output: 16 Explanation: The two words can be "abcw", "xtfn".
Example 2:
Input: words = ["a","ab","abc","d","cd","bcd","abcd"] Output: 4 Explanation: The two words can be "ab", "cd".
Example 3:
Input: words = ["a","aa","aaa","aaaa"] Output: 0 Explanation: No such pair of words.
Constraints:
2 <= words.length <= 10001 <= words[i].length <= 1000words[i]consists only of lowercase English letters.
Solution : bit operation

class Solution {
public int maxProduct(String[] words) {
int length = words.length;
int[] masks = new int[length];
for (int i = 0; i < length; i++) {
String word = words[i];
int wordLength = word.length();
for (int j = 0; j < wordLength; j++) {
masks[i] |= 1 << (word.charAt(j) - 'a');
}
}
int maxProd = 0;
for (int i = 0; i < length; i++) {
for (int j = i + 1; j < length; j++) {
if ((masks[i] & masks[j]) == 0) {
maxProd = Math.max(maxProd, words[i].length() * words[j].length());
}
}
}
return maxProd;
}
}
TC : O(n^2) --> combination of each word is n^2 and O(1) to check if there is an overlap character
SC : O(n) --> bitmask array
167. Two Sum II - Input Array Is Sorted
Given a 1-indexed array of integers numbers that is already sorted in non-decreasing order, find two numbers such that they add up to a specific target number. Let these two numbers be numbers[index1] and numbers[index2] where 1 <= index1 < index2 <= numbers.length.
Return the indices of the two numbers, index1 and index2, added by one as an integer array [index1, index2] of length 2.
The tests are generated such that there is exactly one solution. You may not use the same element twice.
Your solution must use only constant extra space.
Example 1:
Input: numbers = [2,7,11,15], target = 9 Output: [1,2] Explanation: The sum of 2 and 7 is 9. Therefore, index1 = 1, index2 = 2. We return [1, 2].
Example 2:
Input: numbers = [2,3,4], target = 6 Output: [1,3] Explanation: The sum of 2 and 4 is 6. Therefore index1 = 1, index2 = 3. We return [1, 3].
Example 3:
Input: numbers = [-1,0], target = -1 Output: [1,2] Explanation: The sum of -1 and 0 is -1. Therefore index1 = 1, index2 = 2. We return [1, 2].
Constraints:
2 <= numbers.length <= 3 * 104-1000 <= numbers[i] <= 1000numbersis sorted in non-decreasing order.-1000 <= target <= 1000- The tests are generated such that there is exactly one solution.
Solution : use two pointer to solve this problem; Notice that the given array is already sorted. If unsorted, we can use hashMap to solve this problem with TC O(n) and SC O(n)

class Solution {
public int[] twoSum(int[] numbers, int target) {
int low = 0, high = numbers.length - 1;
while (low < high) {
int sum = numbers[low] + numbers[high];
if (sum == target) {
return new int[]{low + 1, high + 1};
} else if (sum < target) {
++low;
} else {
--high;
}
}
return new int[]{-1, -1};
}
}
TC : O(n) --> from border to center
SC : O(1)
209. Minimum Size Subarray Sum
Given an array of positive integers nums and a positive integer target, return the minimal length of a contiguous subarray [numsl, numsl+1, ., numsr-1, numsr] of which the sum is greater than or equal to target. If there is no such subarray, return 0 instead.
Example 1:
Input: target = 7, nums = [2,3,1,2,4,3] Output: 2 Explanation: The subarray [4,3] has the minimal length under the problem constraint.
Example 2:
Input: target = 4, nums = [1,4,4] Output: 1
Example 3:
Input: target = 11, nums = [1,1,1,1,1,1,1,1] Output: 0
Constraints:
1 <= target <= 1091 <= nums.length <= 1051 <= nums[i] <= 104
Follow up: If you have figured out the
O(n) solution, try coding another solution of which the time complexity is O(n log(n)).solution : use sliding window to slove this problem
class Solution {
/*
maintain a sliding window [i, j] and record the sum of this interval
while (sum >= target):
update minLength
i++ (reduce the window length)
*/
public int minSubArrayLen(int target, int[] nums) {
if (nums.length == 0) return 0;
int minLen = Integer.MAX_VALUE;
int i = 0;
int sum = 0;
for (int j = 0; j < nums.length; j++){
sum += nums[j];
while (sum >= target) {
minLen = Math.min(minLen, j - i + 1);
sum -= nums[i++];
}
}
return minLen == Integer.MAX_VALUE ? 0 : minLen;
}
}
TC : O(n) --> linear scan
SC : O(1) const extra space
15. 3Sum
Given an integer array nums, return all the triplets [nums[i], nums[j], nums[k]] such that i != j, i != k, and j != k, and nums[i] + nums[j] + nums[k] == 0.
Notice that the solution set must not contain duplicate triplets.
Example 1:
Input: nums = [-1,0,1,2,-1,-4] Output: [[-1,-1,2],[-1,0,1]] Explanation: nums[0] + nums[1] + nums[1] = (-1) + 0 + 1 = 0. nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0. nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0. The distinct triplets are [-1,0,1] and [-1,-1,2]. Notice that the order of the output and the order of the triplets does not matter.
Example 2:
Input: nums = [0,1,1] Output: [] Explanation: The only possible triplet does not sum up to 0.
Example 3:
Input: nums = [0,0,0] Output: [[0,0,0]] Explanation: The only possible triplet sums up to 0.
Constraints:
3 <= nums.length <= 3000-105 <= nums[i] <= 105
solution : since the TC is not O(n), to remove duplicate, we sort the array first, then we use two pointer to solve this problem.
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
if(nums.length < 3) return new ArrayList<>();
List<List<Integer>> lists = new ArrayList<>();
Arrays.sort(nums); // [-4,-1,-1,0,1,2]
for(int i = 0; i < nums.length - 2; i++){
if(nums[i] > 0) break; // 大于0,后续无解
if(i > 0 && nums[i] == nums[i - 1]) continue; // 跳过重复解
int l = i + 1, r = nums.length - 1;
while(l < r){
if(l > i + 1 && nums[l] == nums[l - 1]){ // 跳过重复解
l++;
continue;
}
int lrSum = nums[l] + nums[r];
if(lrSum == -nums[i]){ // 找到解,加入lists中,移动两个指针
List<Integer> list = new ArrayList<>();
list.add(nums[i]);
list.add(nums[l]);
list.add(nums[r]);
lists.add(list);
l++;
r--;
}
else if (lrSum < -nums[i])l++; // 小于目标,移动左指针
else r--; // 大于目标,移动右指针
}
}
return lists;
}
}
TC : O(n^2) do n twoSum
SC : O(1)
solution : do n times two sum
public class Solution {
public List<List<Integer>> allTriples(int[] array, int target) {
// Write your solution here
Arrays.sort(array);
List<List<Integer>> result = new ArrayList<>();
for (int i = 0; i < array.length - 2; i++){
if (i > 0 && array[i] == array[i - 1]) continue;
int left = i + 1;
int right = array.length - 1;
while (left < right){
int tmp = array[left] + array[right];
if (tmp + array[i] == target){
result.add(Arrays.asList(array[i], array[left], array[right]));
left++;
while(left < right && array[left] == array[left - 1]){
left++;
}
} else if (tmp + array[i] < target){
left++;
} else {
right--;
}
}
}
return result;
}
}
TC : O(n^2) do n twoSum
SC : O(1)
713. Subarray Product Less Than K
Given an array of integers nums and an integer k, return the number of contiguous subarrays where the product of all the elements in the subarray is strictly less than k.
Example 1:
Input: nums = [10,5,2,6], k = 100 Output: 8 Explanation: The 8 subarrays that have product less than 100 are: [10], [5], [2], [6], [10, 5], [5, 2], [2, 6], [5, 2, 6] Note that [10, 5, 2] is not included as the product of 100 is not strictly less than k.
Example 2:
Input: nums = [1,2,3], k = 0 Output: 0
Constraints:
1 <= nums.length <= 3 * 1041 <= nums[i] <= 10000 <= k <= 106
solution : Sliding window
trick : when product of interval [i, j] < k, add j - i + 1 to the result

class Solution {
public int numSubarrayProductLessThanK(int[] nums, int k) {
int n = nums.length, ret = 0;
int prod = 1, i = 0;
for (int j = 0; j < n; j++) {
prod *= nums[j];
while (i <= j && prod >= k) {
prod /= nums[i];
i++;
}
ret += j - i + 1;
}
return ret;
}
}
TC : O(n) n is the length of array.
SC : O(1)
560. Subarray Sum Equals K
Given an array of integers nums and an integer k, return the total number of subarrays whose sum equals to k.
A subarray is a contiguous non-empty sequence of elements within an array.
Example 1:
Input: nums = [1,1,1], k = 2
Output: 2
Example 2:
Input: nums = [1,2,3], k = 3
Output: 2
Constraints:
1 <= nums.length <= 2 * 104-1000 <= nums[i] <= 1000-107 <= k <= 107
Solution1 : Enumerate, for each subarray end at j, go back to see if the sum of the subarray equals to k. TC O(n^3), if we use sum in each loop to record the sum of the subarray, we could do it in TC: O(n^2)

public class Solution {
public int subarraySum(int[] nums, int k) {
int count = 0;
for (int start = 0; start < nums.length; ++start) {
int sum = 0;
for (int end = start; end >= 0; --end) {
sum += nums[end];
if (sum == k) {
count++;
}
}
}
return count;
}
}
TC : O(n^2) --> Enumerate all combination
SC : O(1)
Solution2 : Use prefix sum + hashMap to solve this problem. The bottleneck of the first solution is it needs O(n) time to traverse from i back to 0 to see if there any match cases, but if we can find all match cases in O(1) time, we can reduce the TC to O(n).
We use HashMap to record the prefix sum and the times of the prefix sum appears. From pre[i]−pre[j−1]==k --> we know that pre[j−1] == pre[i] − k. to check the times of pre[j-1]. we use map.get(pre[i] − k) to quickly find out the result. (it is more like use a map to record our moving status)

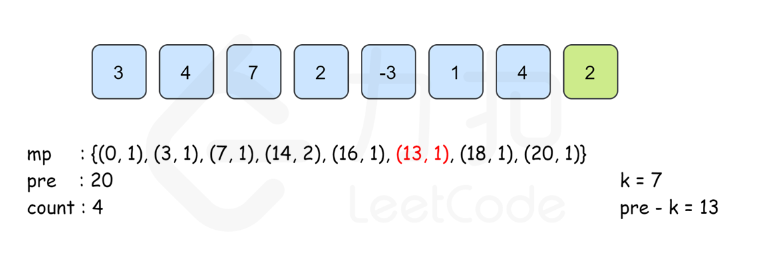
public class Solution {
public int subarraySum(int[] nums, int k) {
int count = 0, pre = 0;
HashMap < Integer, Integer > mp = new HashMap < > ();
mp.put(0, 1);
for (int i = 0; i < nums.length; i++) {
pre += nums[i];
if (mp.containsKey(pre - k)) {
count += mp.get(pre - k);
}
mp.put(pre, mp.getOrDefault(pre, 0) + 1);
}
return count;
}
}
TC : O(n) --> O(1) to find the number of match cases
SC : O(n) --> need record the prefix sum and appear times
525. Contiguous Array
Given a binary array nums, return the maximum length of a contiguous subarray with an equal number of 0 and 1.
Example 1:
Input: nums = [0,1]
Output: 2
Explanation: [0, 1] is the longest contiguous subarray with an equal number of 0 and 1.
Example 2:
Input: nums = [0,1,0]
Output: 2
Explanation: [0, 1] (or [1, 0]) is a longest contiguous subarray with equal number of 0 and 1.
Constraints:
1 <= nums.length <= 105nums[i]is either0or1.
Solution : use prefix sum and hashMap to solve this problem (almost same with the 560). When we calculate the prefix sum, if we meet 0, we can add -1. Use hashMap to record the sum and the first current index. when the sum can be found in map, it means the sum from [map.get(sum) to current index] is 0, update the result.

class Solution {
public int findMaxLength(int[] nums) {
Map<Integer, Integer> map = new HashMap<>();
map.put(0, -1);
int sum = 0;
int globalMax = 0;
for (int i = 0; i < nums.length; i++) {
sum += (nums[i] == 1 ? 1 : -1);
if (map.containsKey(sum)) {
globalMax = Math.max(globalMax, i - map.get(sum));
} else {
map.put(sum, i);
}
}
return globalMax;
}
}
TC : O(n) --> O(1) to get the length
SC : O(n) --> use O(n) hashMap
724. Find Pivot Index
Given an array of integers nums, calculate the pivot index of this array.
The pivot index is the index where the sum of all the numbers strictly to the left of the index is equal to the sum of all the numbers strictly to the index's right.
If the index is on the left edge of the array, then the left sum is 0 because there are no elements to the left. This also applies to the right edge of the array.
Return the leftmost pivot index. If no such index exists, return -1.
Example 1:
Input: nums = [1,7,3,6,5,6] Output: 3 Explanation: The pivot index is 3. Left sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 Right sum = nums[4] + nums[5] = 5 + 6 = 11
Example 2:
Input: nums = [1,2,3] Output: -1 Explanation: There is no index that satisfies the conditions in the problem statement.
Example 3:
Input: nums = [2,1,-1] Output: 0 Explanation: The pivot index is 0. Left sum = 0 (no elements to the left of index 0) Right sum = nums[1] + nums[2] = 1 + -1 = 0
Constraints:
1 <= nums.length <= 104-1000 <= nums[i] <= 1000
Note: This question is the same as 1991: https://leetcode.com/problems/find-the-middle-index-in-array/
Solution : use O(n) space to record prefix sum. Better solution : since left + right + nums[i] == total and left == right; that is 2 * left + nums[i] = total, we don't need to record all prefix sum
class Solution {
public int pivotIndex(int[] nums) {
int total = Arrays.stream(nums).sum();
int sum = 0;
for (int i = 0; i < nums.length; ++i) {
if (2 * sum + nums[i] == total) {
return i;
}
sum += nums[i];
}
return -1;
}
}
TC : O(n)
SC : O(1)
304. Range Sum Query 2D - Immutable
Given a 2D matrix matrix, handle multiple queries of the following type:
- Calculate the sum of the elements of
matrixinside the rectangle defined by its upper left corner(row1, col1)and lower right corner(row2, col2).
Implement the NumMatrix class:
NumMatrix(int[][] matrix)Initializes the object with the integer matrixmatrix.int sumRegion(int row1, int col1, int row2, int col2)Returns the sum of the elements ofmatrixinside the rectangle defined by its upper left corner(row1, col1)and lower right corner(row2, col2).
Example 1:
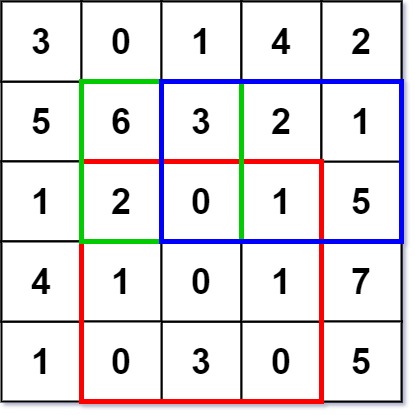
Input ["NumMatrix", "sumRegion", "sumRegion", "sumRegion"] [[[[3, 0, 1, 4, 2], [5, 6, 3, 2, 1], [1, 2, 0, 1, 5], [4, 1, 0, 1, 7], [1, 0, 3, 0, 5]]], [2, 1, 4, 3], [1, 1, 2, 2], [1, 2, 2, 4]] Output [null, 8, 11, 12] Explanation NumMatrix numMatrix = new NumMatrix([[3, 0, 1, 4, 2], [5, 6, 3, 2, 1], [1, 2, 0, 1, 5], [4, 1, 0, 1, 7], [1, 0, 3, 0, 5]]); numMatrix.sumRegion(2, 1, 4, 3); // return 8 (i.e sum of the red rectangle) numMatrix.sumRegion(1, 1, 2, 2); // return 11 (i.e sum of the green rectangle) numMatrix.sumRegion(1, 2, 2, 4); // return 12 (i.e sum of the blue rectangle)
Constraints:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 200-104 <= matrix[i][j] <= 1040 <= row1 <= row2 < m0 <= col1 <= col2 < n- At most
104calls will be made tosumRegion.
Solution : use one-dimension prefix sum(O(min(m,n)) get sum or two-dimension prefix sum (O(1) get sum)
class NumMatrix {
int[][] sums;
public NumMatrix(int[][] matrix) {
int m = matrix.length;
if (m > 0) {
int n = matrix[0].length;
sums = new int[m + 1][n + 1];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
sums[i + 1][j + 1] = sums[i][j + 1] + sums[i + 1][j] - sums[i][j] + matrix[i][j];
}
}
}
}
public int sumRegion(int row1, int col1, int row2, int col2) {
return sums[row2 + 1][col2 + 1] - sums[row1][col2 + 1] - sums[row2 + 1][col1] + sums[row1][col1];
}
}
TC : O(mn) m for row, n for col
SC : O(mn) for prefix array mn
567. Permutation in String
Given two strings s1 and s2, return true if s2 contains a permutation of s1, or false otherwise.
In other words, return true if one of s1's permutations is the substring of s2.
Example 1:
Input: s1 = "ab", s2 = "eidbaooo"
Output: true
Explanation: s2 contains one permutation of s1 ("ba").
Example 2:
Input: s1 = "ab", s2 = "eidboaoo" Output: false
Constraints:
1 <= s1.length, s2.length <= 104s1ands2consist of lowercase English letters.
Solution : use silding window (a map or an array to record the current different character)
class Solution {
public boolean checkInclusion(String s1, String s2) {
// 由于是固定长度,我们只用一个指针i来实现滑动窗口 init 把所有s1的字符添加到map中
Map<Character, Integer> map = new HashMap<>();
for (char ch : s1.toCharArray()) {
map.put(ch, map.getOrDefault(ch, 0) + 1);
}
for (int i = 0; i < s2.length(); i++) {
// 固定长度后,我们只update s1中有的字符, 无论怎样,遍历当前的字符 如果在s1中出现,更新其值
if (map.containsKey(s2.charAt(i))) {
map.put(s2.charAt(i), map.get(s2.charAt(i)) - 1);
}
// 当i长度达到s1之后,往后每次移动,要移除前边的字符,如果不在s1中出现可以不管,因为没有记录
if (i >= s1.length() && map.containsKey(s2.charAt(i - s1.length()))) {
map.put(s2.charAt(i - s1.length()), map.get(s2.charAt(i - s1.length())) + 1);
}
// 判断map中所有元素是否均为0
if (contains(map)) return true;
}
return false;
}
private boolean contains(Map<Character, Integer> map) {
for (Map.Entry<Character, Integer> entry : map.entrySet()) {
if (entry.getValue() != 0) return false;
}
return true;
}
}
TC : O(m + n) -->
SC : O(m)
3. Longest Substring Without Repeating Characters
Given a string s, find the length of the longest substring without repeating characters.
Example 1:
Input: s = "abcabcbb" Output: 3 Explanation: The answer is "abc", with the length of 3.
Example 2:
Input: s = "bbbbb" Output: 1 Explanation: The answer is "b", with the length of 1.
Example 3:
Input: s = "pwwkew" Output: 3 Explanation: The answer is "wke", with the length of 3. Notice that the answer must be a substring, "pwke" is a subsequence and not a substring.
Constraints:
0 <= s.length <= 5 * 104sconsists of English letters, digits, symbols and spaces.
Solution : sliding window (this way like a monotonic stack)
class Solution {
public int lengthOfLongestSubstring(String s) {
int res = 0;
Set<Character> set = new HashSet<>();
int i = 0;
int j = 0;
while (j < s.length()) {
while (set.contains(s.charAt(j))) {
set.remove(s.charAt(i));
i++;
}
set.add(s.charAt(j));
res = Math.max(res, set.size());
j++;
}
return res;
}
}
TC : O(n) -->
SC : O(1) --> max all ascii number 128
125. Valid Palindrome
New API: Charater.isLetterOrDigit(char ch). Charater.toLowerCase(char ch)
A phrase is a palindrome if, after converting all uppercase letters into lowercase letters and removing all non-alphanumeric characters, it reads the same forward and backward. Alphanumeric characters include letters and numbers.
Given a string s, return true if it is a palindrome, or false otherwise.
Example 1:
Input: s = "A man, a plan, a canal: Panama" Output: true Explanation: "amanaplanacanalpanama" is a palindrome.
Example 2:
Input: s = "race a car" Output: false Explanation: "raceacar" is not a palindrome.
Example 3:
Input: s = " " Output: true Explanation: s is an empty string "" after removing non-alphanumeric characters. Since an empty string reads the same forward and backward, it is a palindrome.
Constraints:
1 <= s.length <= 2 * 105sconsists only of printable ASCII characters.
Solution : use two pointer to solve this problem
class Solution {
public boolean isPalindrome(String s) {
char[] input = s.toCharArray();
int i = 0;
int j = input.length - 1;
while (i < j) {
while (i < j && !Character.isLetterOrDigit(input[i])) {
i++;
}
while (i < j && !Character.isLetterOrDigit(input[j])) {
j--;
}
if (Character.toLowerCase(input[i++]) != Character.toLowerCase(input[j--]) ) return false;
}
return true;
}
}
TC : O(n) --> n is the length of String s
SC : O(1)
647. Palindromic Substrings
Given a string s, return the number of palindromic substrings in it.
A string is a palindrome when it reads the same backward as forward.
A substring is a contiguous sequence of characters within the string.
Example 1:
Input: s = "abc" Output: 3 Explanation: Three palindromic strings: "a", "b", "c".
Example 2:
Input: s = "aaa" Output: 6 Explanation: Six palindromic strings: "a", "a", "a", "aa", "aa", "aaa".
Constraints:
1 <= s.length <= 1000sconsists of lowercase English letters.
Solution : Center expension. If we use two forloop and check from i to j whether it is palindrome, it will take O(n^3), use center expension only take O(n^2)
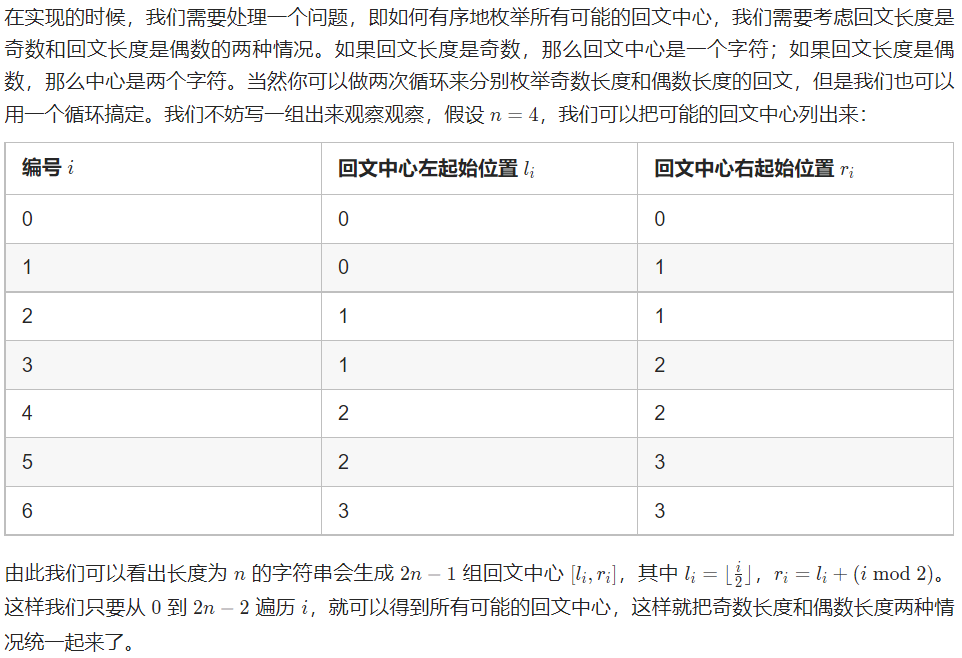
class Solution {
public int countSubstrings(String s) {
int n = s.length(), ans = 0;
for (int i = 0; i < 2 * n - 1; ++i) {
int l = i / 2, r = i - l;
while (l >= 0 && r < n && s.charAt(l) == s.charAt(r)) {
--l;
++r;
++ans;
}
}
return ans;
}
}
TC : O(n^2)
SC : O(1)
680. Valid Palindrome II
Given a string s, return true if the s can be palindrome after deleting at most one character from it.
Example 1:
Input: s = "aba" Output: true
Example 2:
Input: s = "abca" Output: true Explanation: You could delete the character 'c'.
Example 3:
Input: s = "abc" Output: false
Constraints:
1 <= s.length <= 105sconsists of lowercase English letters.
Solution : Use two pointer to solve this problem
class Solution {
public boolean validPalindrome(String s) {
for (int i = 0, j = s.length() - 1; i < j; i++, j--) {
// since we can jump one character, we have two choice, left or right, we need check them both and return the or result.
if (s.charAt(i) != s.charAt(j)) return isPalindrome(s, i + 1, j) || isPalindrome(s, i, j - 1);
}
return true;
}
private boolean isPalindrome(String s, int i, int j) {
while (i < j) {
if (s.charAt(i++) != s.charAt(j--)) return false;
}
return true;
}
}
TC : O(n)
SC : O(1)
19. Remove Nth Node From End of List
Given the head of a linked list, remove the nth node from the end of the list and return its head.
Example 1:

Input: head = [1,2,3,4,5], n = 2 Output: [1,2,3,5]
Example 2:
Input: head = [1], n = 1 Output: []
Example 3:
Input: head = [1,2], n = 1 Output: [1]
Constraints:
- The number of nodes in the list is
sz. 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
Follow up: Could you do this in one pass?
Solution1 : get the length of linked list first and remove
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode cur = dummy;
int counter = 0;
ListNode lenNode = head;
int len = getLength(lenNode);
while (cur != null) {
if (counter == len - n) {
cur.next = cur.next.next;
break;
}
cur = cur.next;
counter++;
}
return dummy.next;
}
private int getLength(ListNode head) {
int len = 0;
while (head != null) {
len++;
head = head.next;
}
return len;
}
}
TC : O(n)
SC : O(1)
Solution2 : two pointer, keep a distance n between P1 and P2, when P2 goes to the end, p1 is the node we wanna remove.
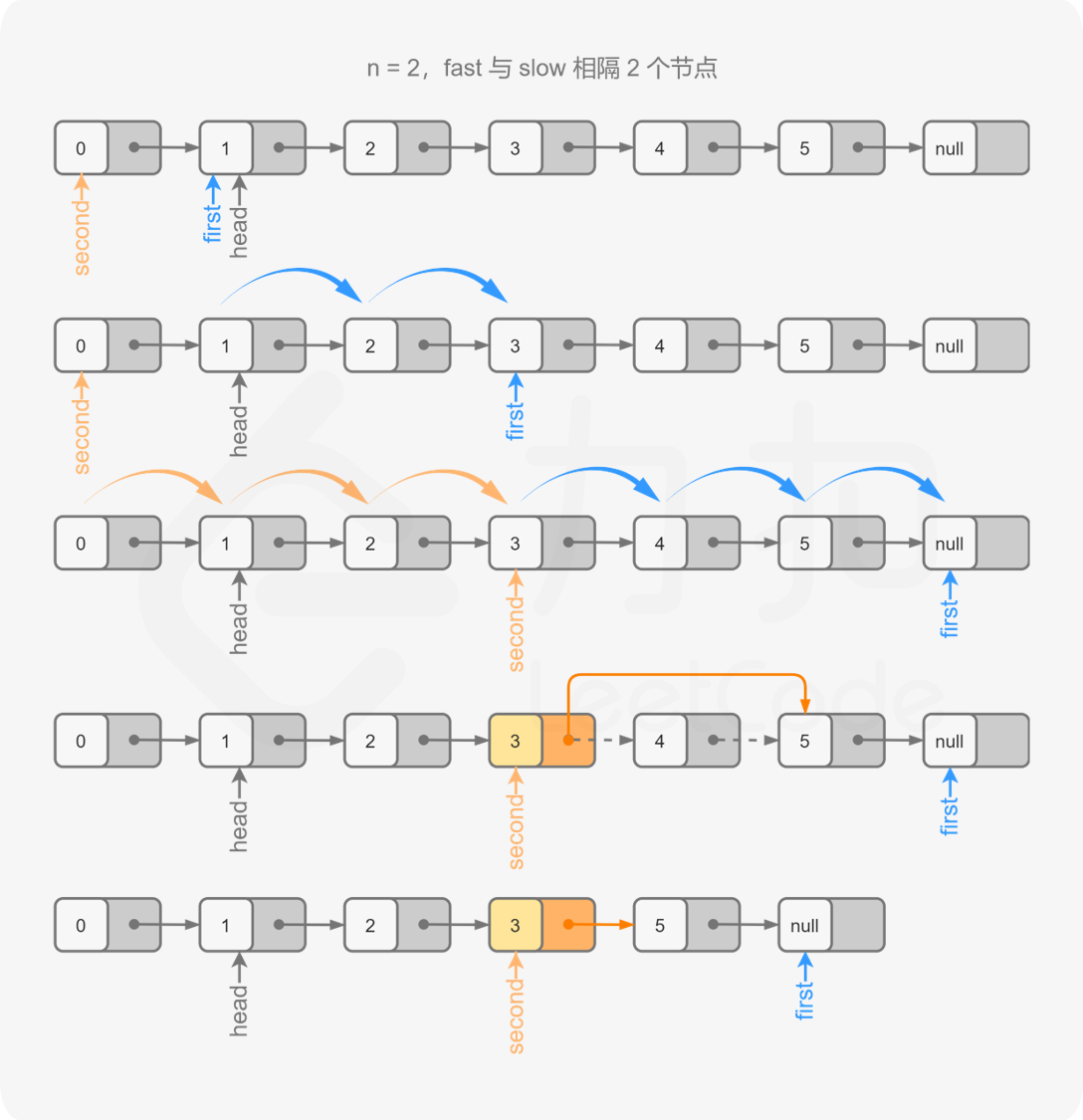
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(0, head);
ListNode first = head;
ListNode second = dummy;
for (int i = 0; i < n; ++i) {
first = first.next;
}
while (first != null) {
first = first.next;
second = second.next;
}
second.next = second.next.next;
ListNode ans = dummy.next;
return ans;
}
}
TC : O(n)
SC : O(1)
142. Linked List Cycle II
Given the head of a linked list, return the node where the cycle begins. If there is no cycle, return null.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail's next pointer is connected to (0-indexed). It is -1 if there is no cycle. Note that pos is not passed as a parameter.
Do not modify the linked list.
Example 1:

Input: head = [3,2,0,-4], pos = 1 Output: tail connects to node index 1 Explanation: There is a cycle in the linked list, where tail connects to the second node.
Example 2:
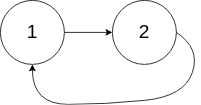
Input: head = [1,2], pos = 0 Output: tail connects to node index 0 Explanation: There is a cycle in the linked list, where tail connects to the first node.
Example 3:

Input: head = [1], pos = -1 Output: no cycle Explanation: There is no cycle in the linked list.
Constraints:
- The number of the nodes in the list is in the range
[0, 104]. -105 <= Node.val <= 105posis-1or a valid index in the linked-list.
Follow up: Can you solve it using O(1) (i.e. constant) memory?
Solution : Easy way to do is HashSet, record all visited node but that needs SC O(n). We use two pointer(slow and fast) instead.
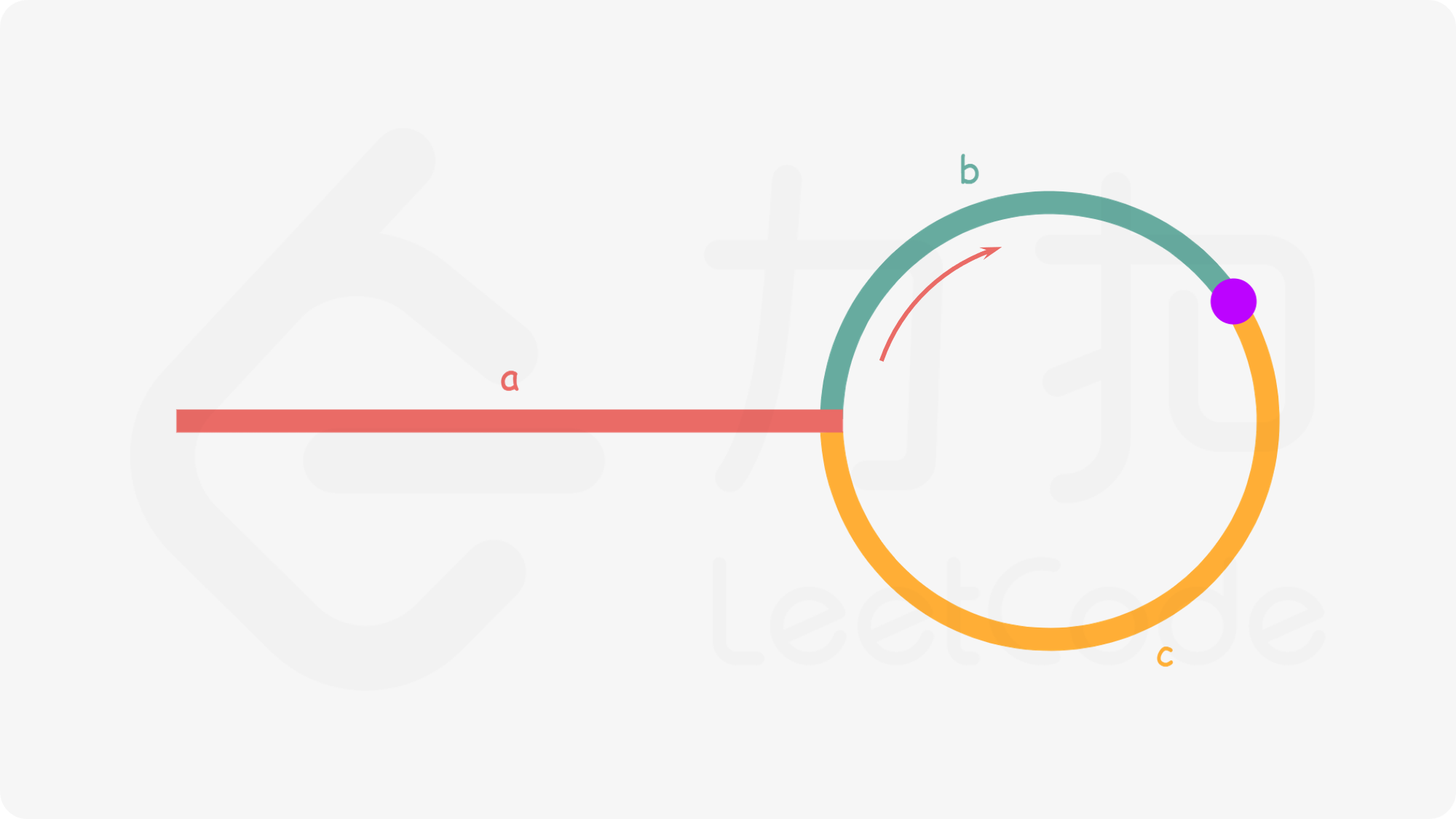
1. initialize fast and slow pointer, the fast pointer move two step each time and slow pointer move one step each time.
2. two pointers both start from head, if there is a circle, they will always meet again.
3. Details
- suppose fast moves 2k steps and slow moves k steps.
- There are a nodes from head to the entry of the circle.
- When two pointers meet in the circle, slow moves b nodes from the entry node. and the left nodes of the circle is c. suppose circle has T = (b + c) nodes.
1. Now we have:
1) k - a = b
2) 2k - a = nT + b
2. use 2) minue 1) we get:
3) k = nT = (n - 1) * T + b + c
3. use 3) minus 1) we have:
4) a = (n - 1)T + c
4. now we have a % T = c, we reset the fast to head. when fast move (n - 1) * T + c, we find the slow pointer will also move to the entry.
5. The stop case is slow == fast, return slow/fast
public class Solution {
public ListNode detectCycle(ListNode head) {
if(head == null || head.next == null) return null; // corner case
ListNode fast = head, slow = head;
while(fast != null && fast.next != null){
fast = fast.next.next;
slow = slow.next;
if(slow == fast) break; // meet
}
if(slow != fast) return null; // if there is no circle return null. without whis condition, fast will NPE.
fast = head; // reset fast to head;
while(slow != fast){
fast = fast.next;
slow = slow.next;
}
return slow; // return fast both works
}
}
TC : O(n)
SC : O(1) --> only three pointer
160. Intersection of Two Linked Lists
Given the heads of two singly linked-lists headA and headB, return the node at which the two lists intersect. If the two linked lists have no intersection at all, return null.
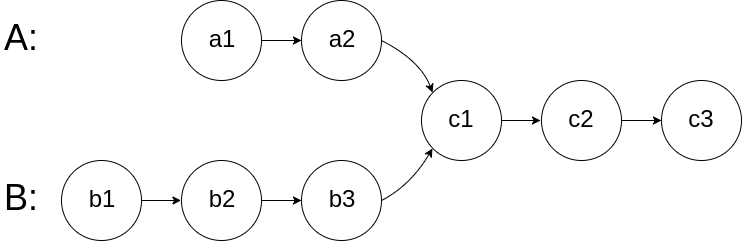
For example, the following two linked lists begin to intersect at node c1:
The test cases are generated such that there are no cycles anywhere in the entire linked structure.
Note that the linked lists must retain their original structure after the function returns.
Custom Judge:
The inputs to the judge are given as follows (your program is not given these inputs):
intersectVal- The value of the node where the intersection occurs. This is0if there is no intersected node.listA- The first linked list.listB- The second linked list.skipA- The number of nodes to skip ahead inlistA(starting from the head) to get to the intersected node.skipB- The number of nodes to skip ahead inlistB(starting from the head) to get to the intersected node.
The judge will then create the linked structure based on these inputs and pass the two heads, headA and headB to your program. If you correctly return the intersected node, then your solution will be accepted.
Example 1:

Input: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3 Output: Intersected at '8' Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,6,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.
Example 2:

Input: intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1 Output: Intersected at '2' Explanation: The intersected node's value is 2 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [1,9,1,2,4]. From the head of B, it reads as [3,2,4]. There are 3 nodes before the intersected node in A; There are 1 node before the intersected node in B.
Example 3:
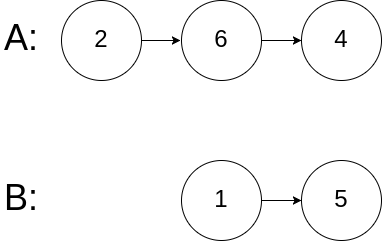
Input: intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2 Output: No intersection Explanation: From the head of A, it reads as [2,6,4]. From the head of B, it reads as [1,5]. Since the two lists do not intersect, intersectVal must be 0, while skipA and skipB can be arbitrary values. Explanation: The two lists do not intersect, so return null.
Constraints:
- The number of nodes of
listAis in them. - The number of nodes of
listBis in then. 1 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA < m0 <= skipB < nintersectValis0iflistAandlistBdo not intersect.intersectVal == listA[skipA] == listB[skipB]iflistAandlistBintersect.
Follow up: Could you write a solution that runs in
O(m + n) time and use only O(1) memory?
Solution : two pointer
方法:双指针
思路和算法
使用双指针的方法,可以将空间复杂度降至 O(1)O(1)。
只有当链表 headA 和 headB 都不为空时,两个链表才可能相交。因此首先判断链表 headA 和 headB 是否为空,如果其中至少有一个链表为空,则两个链表一定不相交,返回 null。
当链表 headA 和 headB 都不为空时,创建两个指针 pA 和 pB,初始时分别指向两个链表的头节点 headA 和 headB,然后将两个指针依次遍历两个链表的每个节点。具体做法如下:
每步操作需要同时更新指针 pA 和 pB。
如果指针 pA 不为空,则将指针 pA 移到下一个节点;如果指针 pB 不为空,则将指针 pB 移到下一个节点。
如果指针 pA 为空,则将指针 pA 移到链表 headB 的头节点;如果指针 pB 为空,则将指针 pB 移到链表 headA 的头节点。
当指针 pA 和 pB 指向同一个节点或者都为空时,返回它们指向的节点或者 null。
证明:
下面提供双指针方法的正确性证明。考虑两种情况,第一种情况是两个链表相交,第二种情况是两个链表不相交。
情况一:两个链表相交
链表 headA 和 headB 的长度分别是 mm 和 nn。假设链表 headA 的不相交部分有 aa 个节点,链表 headB 的不相交部分有 bb 个节点,两个链表相交的部分有 cc 个节点,则有 a+c=ma+c=m,b+c=nb+c=n。
如果 a=b,则两个指针会同时到达两个链表相交的节点,此时返回相交的节点;
如果 a != b 则指针 pA 会遍历完链表 headA,指针 pB 会遍历完链表 headB,两个指针不会同时到达链表的尾节点,然后指针 pA 移到链表 headB 的头节点,指针 pB 移到链表 headA 的头节点,然后两个指针继续移动,在指针 pA 移动了 a+c+ba+c+b 次、指针 pB 移动了 b+c+ab+c+a 次之后,两个指针会同时到达两个链表相交的节点,该节点也是两个指针第一次同时指向的节点,此时返回相交的节点。
情况二:两个链表不相交
链表 headA 和 headB 的长度分别是 mm 和 nn。考虑当 m=nm=n 和 m \ne nm
=n 时,两个指针分别会如何移动:
如果 m = n,则两个指针会同时到达两个链表的尾节点,然后同时变成空值 null,此时返回 null;
如果 m != n 则由于两个链表没有公共节点,两个指针也不会同时到达两个链表的尾节点,因此两个指针都会遍历完两个链表,在指针 pA 移动了 m+nm+n 次、指针 pB 移动了 n+mn+m 次之后,两个指针会同时变成空值 null,此时返回 null。
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
ListNode pA = headA, pB = headB;
while (pA != pB) {
pA = pA == null ? headB : pA.next;
pB = pB == null ? headA : pB.next;
}
return pA;
}
}
TC : O(n + m)
SC : O(1)
206. Reverse Linked List
Given the head of a singly linked list, reverse the list, and return the reversed list.
Example 1:

Input: head = [1,2,3,4,5] Output: [5,4,3,2,1]
Example 2:

Input: head = [1,2] Output: [2,1]
Example 3:
Input: head = [] Output: []
Constraints:
- The number of nodes in the list is the range
[0, 5000]. -5000 <= Node.val <= 5000
Follow up: A linked list can be reversed either iteratively or recursively. Could you implement both?
Solution1 : Iteration
prev = null;
1 -> 2 -> 3 -> 4 -> 5
null <- 1 2 -> 3 -> 4 -> 5
prev c n
null <- 1 <- 2 3 -> 4 -> 5
prev c n
class Solution {
public ListNode reverseList(ListNode head) {
if (head == null) return head;
ListNode prev = null;
ListNode next = null;
ListNode cur = head;
while (cur != null) {
next = cur.next;
cur.next = prev;
prev = cur;
cur = next;
}
return prev;
}
}
TC : O(n)
SC : O(1)
Solution2 : recursive
class Solution {
public ListNode reverseList(ListNode head) {
// base case
if (head == null || head.next == null) return head;
ListNode newHead = reverseList(head.next);
head.next.next = head;
head.next = null;
return newHead;
}
}
TC : O(n)
SC : O(n) heap is O(1) + call stack is O(n)
445. Add Two Numbers II
You are given two non-empty linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
Example 1:
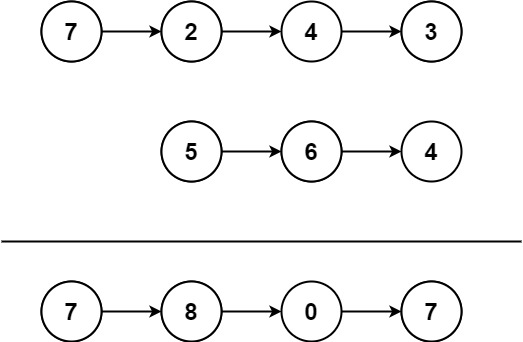
Input: l1 = [7,2,4,3], l2 = [5,6,4] Output: [7,8,0,7]
Example 2:
Input: l1 = [2,4,3], l2 = [5,6,4] Output: [8,0,7]
Example 3:
Input: l1 = [0], l2 = [0] Output: [0]
Constraints:
- The number of nodes in each linked list is in the range
[1, 100]. 0 <= Node.val <= 9- It is guaranteed that the list represents a number that does not have leading zeros.
Follow up: Could you solve it without reversing the input lists?
Solution1 : it's more like the merge two linked list
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
l1 = reverse(l1);
l2 = reverse(l2);
int carry = 0;
ListNode newHead = new ListNode(0);
ListNode cur = newHead;
while (l1 != null || l2 != null) {
int sum = carry;
if (l1 != null) {
sum += l1.val;
l1 = l1.next;
}
if (l2 != null) {
sum += l2.val;
l2 = l2.next;
}
carry = sum / 10;
cur.next = new ListNode(sum % 10);
cur = cur.next;
}
if (carry != 0) {
cur.next = new ListNode(1);
}
return reverse(newHead.next);
}
private ListNode reverse(ListNode l1) {
ListNode prev = null;
ListNode next = null;
while (l1 != null) {
next = l1.next;
l1.next = prev;
prev = l1;
l1 = next;
}
return prev;
}
}
Also could use stack to replace the reverse operation
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
Deque<Integer> stack1 = new ArrayDeque<Integer>();
Deque<Integer> stack2 = new ArrayDeque<Integer>();
while (l1 != null) {
stack1.push(l1.val);
l1 = l1.next;
}
while (l2 != null) {
stack2.push(l2.val);
l2 = l2.next;
}
int carry = 0;
ListNode ans = null;
while (!stack1.isEmpty() || !stack2.isEmpty() || carry != 0) {
int a = stack1.isEmpty() ? 0 : stack1.pop();
int b = stack2.isEmpty() ? 0 : stack2.pop();
int cur = a + b + carry;
carry = cur / 10;
cur %= 10;
ListNode curnode = new ListNode(cur);
curnode.next = ans;
ans = curnode;
}
return ans;
}
}
TC : O(n + m)
SC : O(m + n) stack, if use reverse SC is O(1)
234. Palindrome Linked List
Given the head of a singly linked list, return true if it is a palindrome.
Example 1:

Input: head = [1,2,2,1] Output: true
Example 2:
Input: head = [1,2] Output: false
Constraints:
- The number of nodes in the list is in the range
[1, 105]. 0 <= Node.val <= 9
Follow up: Could you do it in
O(n) time and O(1) space?
Solution1 : use array and two pointer to solve this problem, but this is not a smart way.
Solution1 : recursion (SC still O(n) call stack)
we use a global variable frontNode to traverse from the head, and use the recusive way to compare the Node in the end, this is another way of two pointers.
class Solution {
private ListNode frontPointer;
private boolean recursivelyCheck(ListNode currentNode) {
if (currentNode != null) {
if (!recursivelyCheck(currentNode.next)) {
return false;
}
if (currentNode.val != frontPointer.val) {
return false;
}
frontPointer = frontPointer.next;
}
return true;
}
public boolean isPalindrome(ListNode head) {
frontPointer = head;
return recursivelyCheck(head);
}
}
TC : O(n)
SC : O(n) call stack space
Solution3 :
1.use fast - slow pointer to get middle of the linked list.
2.reverse slow.next
3.compare two linkedList
1) case 1, length is even:
0 1 2 3 4 5
1 2 3 1 2 3
f
s
2) case 2, length is odd:
0 1 2 3 4
1 2 3 1 2
s
f
in both cases, we just need to reverse the slow.next and compare the two linkedList from the head;
class Solution {
public boolean isPalindrome(ListNode head) {
ListNode slow = getMiddle(head);
ListNode l2 = reverse(slow.next);
slow.next = null;
while (head != null && l2 != null) {
if (head.val != l2.val) return false;
head = head.next;
l2 = l2.next;
}
return true;
}
private ListNode reverse(ListNode head) {
ListNode prev = null;
ListNode next = null;
while (head != null) {
next = head.next;
head.next = prev;
prev = head;
head = next;
}
return prev;
}
private ListNode getMiddle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while (fast.next != null && fast.next.next != null) {
fast = fast.next.next;
slow = slow.next;
}
return slow;
}
}
TC : O(n)
SC : O(1)
430. Flatten a Multilevel Doubly Linked List
You are given a doubly linked list, which contains nodes that have a next pointer, a previous pointer, and an additional child pointer. This child pointer may or may not point to a separate doubly linked list, also containing these special nodes. These child lists may have one or more children of their own, and so on, to produce a multilevel data structure as shown in the example below.
Given the head of the first level of the list, flatten the list so that all the nodes appear in a single-level, doubly linked list. Let curr be a node with a child list. The nodes in the child list should appear after curr and before curr.next in the flattened list.
Return the head of the flattened list. The nodes in the list must have all of their child pointers set to null.
Example 1:
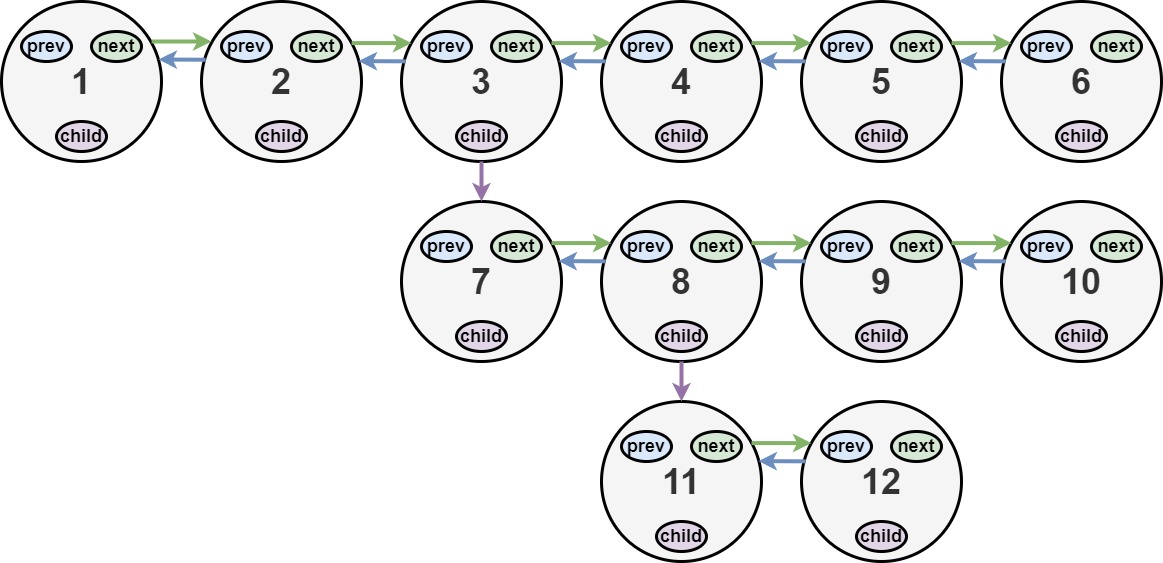
Input: head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12] Output: [1,2,3,7,8,11,12,9,10,4,5,6] Explanation: The multilevel linked list in the input is shown. After flattening the multilevel linked list it becomes:
Example 2:

Input: head = [1,2,null,3] Output: [1,3,2] Explanation: The multilevel linked list in the input is shown. After flattening the multilevel linked list it becomes:
Example 3:
Input: head = [] Output: [] Explanation: There could be empty list in the input.
Constraints:
- The number of Nodes will not exceed
1000. 1 <= Node.val <= 105
How the multilevel linked list is represented in test cases:
We use the multilevel linked list from Example 1 above:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
The serialization of each level is as follows:
[1,2,3,4,5,6,null] [7,8,9,10,null] [11,12,null]
To serialize all levels together, we will add nulls in each level to signify no node connects to the upper node of the previous level. The serialization becomes:
[1, 2, 3, 4, 5, 6, null]
|
[null, null, 7, 8, 9, 10, null]
|
[ null, 11, 12, null]
Merging the serialization of each level and removing trailing nulls we obtain:
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
708. Insert into a Sorted Circular Linked List
Given a Circular Linked List node, which is sorted in ascending order, write a function to insert a value insertVal into the list such that it remains a sorted circular list. The given node can be a reference to any single node in the list and may not necessarily be the smallest value in the circular list.
If there are multiple suitable places for insertion, you may choose any place to insert the new value. After the insertion, the circular list should remain sorted.
If the list is empty (i.e., the given node is null), you should create a new single circular list and return the reference to that single node. Otherwise, you should return the originally given node.
Example 1:
Input: head = [3,4,1], insertVal = 2 Output: [3,4,1,2] Explanation: In the figure above, there is a sorted circular list of three elements. You are given a reference to the node with value 3, and we need to insert 2 into the list. The new node should be inserted between node 1 and node 3. After the insertion, the list should look like this, and we should still return node 3.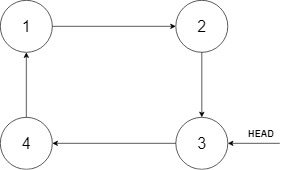
Example 2:
Input: head = [], insertVal = 1
Output: [1]
Explanation: The list is empty (given head is null). We create a new single circular list and return the reference to that single node.
Example 3:
Input: head = [1], insertVal = 0 Output: [1,0]
Constraints:
- The number of nodes in the list is in the range
[0, 5 * 104]. -106 <= Node.val, insertVal <= 106
Solution1 : iteration
we have three cases to insert:
1.commen case: prev <= insert <= cur
2. insert between end and start of the linkedlist:
1) 4, 1 insert 0/1
(prev.val > cur.val && cur.val >= insertVal)
2) 4, 1 insert 4/5
(prev.val > cur.val && insertVal >= prev.val)
when we meet these three cases, just stop,
insert between prev and current node.
class Solution {
public Node insert(Node head, int insertVal) {
if (head == null) {
Node res = new Node(insertVal);
res.next = res;
return res;
}
if (head.next == head) {
head.next = new Node(insertVal, head.next);
return head;
}
Node prev = head;
Node cur = head.next;
while (cur != head) {
// here is three cases we need to insert
if ( (cur.val >= insertVal && prev.val <= insertVal) || (prev.val > cur.val && cur.val >= insertVal) || (prev.val > cur.val && insertVal >= prev.val) ) break;
prev = prev.next;
cur = cur.next;
}
prev.next = new Node(insertVal, prev.next);
return head;
}
}
TC : O(n)
SC : O(1)
380. Insert Delete GetRandom O(1)
Implement the RandomizedSet class:
RandomizedSet()Initializes theRandomizedSetobject.bool insert(int val)Inserts an itemvalinto the set if not present. Returnstrueif the item was not present,falseotherwise.bool remove(int val)Removes an itemvalfrom the set if present. Returnstrueif the item was present,falseotherwise.int getRandom()Returns a random element from the current set of elements (it's guaranteed that at least one element exists when this method is called). Each element must have the same probability of being returned.
You must implement the functions of the class such that each function works in average O(1) time complexity.
Example 1:
Input ["RandomizedSet", "insert", "remove", "insert", "getRandom", "remove", "insert", "getRandom"] [[], [1], [2], [2], [], [1], [2], []] Output [null, true, false, true, 2, true, false, 2] Explanation RandomizedSet randomizedSet = new RandomizedSet(); randomizedSet.insert(1); // Inserts 1 to the set. Returns true as 1 was inserted successfully. randomizedSet.remove(2); // Returns false as 2 does not exist in the set. randomizedSet.insert(2); // Inserts 2 to the set, returns true. Set now contains [1,2]. randomizedSet.getRandom(); // getRandom() should return either 1 or 2 randomly. randomizedSet.remove(1); // Removes 1 from the set, returns true. Set now contains [2]. randomizedSet.insert(2); // 2 was already in the set, so return false. randomizedSet.getRandom(); // Since 2 is the only number in the set, getRandom() will always return 2.
Constraints:
-231 <= val <= 231 - 1- At most
2 *105calls will be made toinsert,remove, andgetRandom. - There will be at least one element in the data structure when
getRandomis called.
Solution : Use List and HashMap to solve this problem in O(1)
Use hashmap we can do contains in O(1)
Use list we can do insert and remove in O(1)
Use their combination, we can solve this problem in O(1)
The hardest part is the remove: how to remove in O(1) in a list without reset index
map 0 1 2 3 4
suppose list is [1, 2, 3, 4, 5]
we want to remove 3 from the list
1. put the last element of the list to the index of 3, reset 5's index in map to 2
2. delete key 3 in map
map 0 1 2 3
suppose list is [1, 2, 5, 4]
class RandomizedSet {
Map<Integer, Integer> map;
List<Integer> list;
Random random;
/** Initialize your data structure here. */
public RandomizedSet() {
map = new HashMap<>();
list = new ArrayList<>();
random = new Random();
}
/** Inserts a value to the set. Returns true if the set did not already contain the specified element. */
public boolean insert(int val) {
if (map.containsKey(val)) return false;
else {
map.put(val, list.size());
list.add(val);
return true;
}
}
/** Removes a value from the set. Returns true if the set contained the specified element. */
public boolean remove(int val) {
if (map.containsKey(val)) {
int index = map.get(val);
int last = list.get(list.size() - 1);
list.set(index, last);
map.put(last, index);
list.remove(list.size() - 1);
map.remove(val);
return true;
} else {
return false;
}
}
/** Get a random element from the set. */
public int getRandom() {
int ran = random.nextInt(list.size());
return list.get(ran);
}
}
TC : O(1)
SC : O(n)
242. Valid Anagram
Solution : sliding window, use map/array can solve this problem in SC: O(n). With bit operation, it can be solved in SC: O(1). Here we use bit operation to solve this problem
class Solution {
public boolean isAnagram(String s, String t) {
if (s.equals(t) || s.length() != t.length()) return false;
int res1 = 0;
int res2 = 0;
for (int i = 0; i < s.length(); i++) {
res1 ^= ((1 << (s.charAt(i) - 'a')) ^ (1 << (t.charAt(i) - 'a')));
res2 += ((1 << (s.charAt(i) - 'a')) - (1 << (t.charAt(i) - 'a')));
}
return (res1 == 0) && (res2 == 0);
}
}
TC : O(n)
SC : O(1)
146. LRU Cache
Design a data structure that follows the constraints of a Least Recently Used (LRU) cache.
Implement the LRUCache class:
LRUCache(int capacity)Initialize the LRU cache with positive sizecapacity.int get(int key)Return the value of thekeyif the key exists, otherwise return-1.void put(int key, int value)Update the value of thekeyif thekeyexists. Otherwise, add thekey-valuepair to the cache. If the number of keys exceeds thecapacityfrom this operation, evict the least recently used key.
The functions get and put must each run in O(1) average time complexity.
Example 1:
Input
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
Output
[null, null, null, 1, null, -1, null, -1, 3, 4]
Explanation
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // cache is {1=1}
lRUCache.put(2, 2); // cache is {1=1, 2=2}
lRUCache.get(1); // return 1
lRUCache.put(3, 3); // LRU key was 2, evicts key 2, cache is {1=1, 3=3}
lRUCache.get(2); // returns -1 (not found)
lRUCache.put(4, 4); // LRU key was 1, evicts key 1, cache is {4=4, 3=3}
lRUCache.get(1); // return -1 (not found)
lRUCache.get(3); // return 3
lRUCache.get(4); // return 4
Constraints:
1 <= capacity <= 30000 <= key <= 1040 <= value <= 105- At most 2
* 105calls will be made togetandput.
Solution : 哈希表-双向链表
方法一:哈希表 + 双向链表
算法
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
-
双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
-
哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 的时间内完成 get 或者 put 操作。具体的方法如下:
-
对于
get操作,首先判断key是否存在:-
如果
key不存在,则返回 ; -
如果
key存在,则key对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
-
-
对于
put操作,首先判断key是否存在:-
如果
key不存在,使用key和value创建一个新的节点,在双向链表的头部添加该节点,并将key和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项; -
如果
key存在,则与get操作类似,先通过哈希表定位,再将对应的节点的值更新为value,并将该节点移到双向链表的头部。
-
上述各项操作中,访问哈希表的时间复杂度为 ,在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 时间内完成。
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
TC : O(1)
SC : O(n)
49. Group Anagrams
Given an array of strings strs, group the anagrams together. You can return the answer in any order.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
Example 1:
Input: strs = ["eat","tea","tan","ate","nat","bat"] Output: [["bat"],["nat","tan"],["ate","eat","tea"]]
Example 2:
Input: strs = [""] Output: [[""]]
Example 3:
Input: strs = ["a"] Output: [["a"]]
Constraints:
1 <= strs.length <= 1040 <= strs[i].length <= 100strs[i]consists of lowercase English letters.
Solution : sort the String and use the map to solve this problem
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<String, List<String>>();
for (String str : strs) {
char[] array = str.toCharArray();
Arrays.sort(array);
String key = new String(array);
List<String> list = map.getOrDefault(key, new ArrayList<String>());
list.add(str);
map.put(key, list);
}
return new ArrayList<List<String>>(map.values());
}
}
TC : O(nk logk) n is the number of string, k is the lonest length of string, need k log k time to sort.
SC : O(nk) map
Solution2 : Count
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<String, List<String>>();
for (String str : strs) {
int[] counts = new int[26];
int length = str.length();
for (int i = 0; i < length; i++) {
counts[str.charAt(i) - 'a']++;
}
// 将每个出现次数大于 0 的字母和出现次数按顺序拼接成字符串,作为哈希表的键
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 26; i++) {
if (counts[i] != 0) {
sb.append((char) ('a' + i));
sb.append(counts[i]);
}
}
String key = sb.toString();
List<String> list = map.getOrDefault(key, new ArrayList<String>());
list.add(str);
map.put(key, list);
}
return new ArrayList<List<String>>(map.values());
}
}
TC : O(nk logk) n is the number of string, k is the lonest length of string, need k log k time to sort.
SC : O(nk) map
953. Verifying an Alien Dictionary
In an alien language, surprisingly, they also use English lowercase letters, but possibly in a different order. The order of the alphabet is some permutation of lowercase letters.
Given a sequence of words written in the alien language, and the order of the alphabet, return true if and only if the given words are sorted lexicographically in this alien language.
Example 1:
Input: words = ["hello","leetcode"], order = "hlabcdefgijkmnopqrstuvwxyz" Output: true Explanation: As 'h' comes before 'l' in this language, then the sequence is sorted.
Example 2:
Input: words = ["word","world","row"], order = "worldabcefghijkmnpqstuvxyz" Output: false Explanation: As 'd' comes after 'l' in this language, then words[0] > words[1], hence the sequence is unsorted.
Example 3:
Input: words = ["apple","app"], order = "abcdefghijklmnopqrstuvwxyz" Output: false Explanation: The first three characters "app" match, and the second string is shorter (in size.) According to lexicographical rules "apple" > "app", because 'l' > '∅', where '∅' is defined as the blank character which is less than any other character (More info).
Constraints:
1 <= words.length <= 1001 <= words[i].length <= 20order.length == 26- All characters in
words[i]andorderare English lowercase letters.
solution : use simple iteration
class Solution {
public boolean isAlienSorted(String[] words, String order) {
Map<Character, Integer> map = new HashMap<>();
// initialize map
int j = 0;
for (char ch : order.toCharArray()) {
map.put(ch, j++);
}
//
for (int i = 0; i < words.length - 1; i++) {
if (!check (words[i], words[i + 1], map)) {
return false;
}
}
return true;
}
private boolean check(String s1, String s2, Map<Character, Integer> map) {
for (int i = 0; i < s1.length(); i++) {
if (i >= s2.length()) return false;
if (s1.charAt(i) == s2.charAt(i)) continue;
else if (map.get(s1.charAt(i)) > map.get(s2.charAt(i))) return false;
else return true;
}
return true;
}
}
TC : O(mn) --> n is the num of array, m is the average length of string
SC : O(C) --> map, distinc character C = 26
539. Minimum Time Difference
Example 1:
Input: timePoints = ["23:59","00:00"] Output: 1
Example 2:
Input: timePoints = ["00:00","23:59","00:00"] Output: 0
Constraints:
2 <= timePoints.length <= 2 * 104timePoints[i]is in the format "HH:MM".
Solution : Sort the array first and compare current and previous string iteratively.
class Solution {
public int findMinDifference(List<String> timePoints) {
int n = timePoints.size();
// the pigeonhole principle (鸽巢原理)
if (n > 1440) {
return 0;
}
// sort the array first
Collections.sort(timePoints);
int ans = Integer.MAX_VALUE;
int t0Minutes = getMinutes(timePoints.get(0));
int preMinutes = t0Minutes;
for (int i = 1; i < n; ++i) {
int minutes = getMinutes(timePoints.get(i));
ans = Math.min(ans, minutes - preMinutes); // 相邻时间的时间差
preMinutes = minutes;
}
ans = Math.min(ans, t0Minutes + 1440 - preMinutes); // 首尾时间的时间差 start to end
return ans;
}
public int getMinutes(String t) {
return ((t.charAt(0) - '0') * 10 + (t.charAt(1) - '0')) * 60 + (t.charAt(3) - '0') * 10 + (t.charAt(4) - '0');
}
}
TC : O(nlogn) sort time
SC : O(n) sorted array
150. Evaluate Reverse Polish Notation
Evaluate the value of an arithmetic expression in Reverse Polish Notation.
Valid operators are +, -, *, and /. Each operand may be an integer or another expression.
Note that division between two integers should truncate toward zero.
It is guaranteed that the given RPN expression is always valid. That means the expression would always evaluate to a result, and there will not be any division by zero operation.
Example 1:
Input: tokens = ["2","1","+","3","*"] Output: 9 Explanation: ((2 + 1) * 3) = 9
Example 2:
Input: tokens = ["4","13","5","/","+"] Output: 6 Explanation: (4 + (13 / 5)) = 6
Example 3:
Input: tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"] Output: 22 Explanation: ((10 * (6 / ((9 + 3) * -11))) + 17) + 5 = ((10 * (6 / (12 * -11))) + 17) + 5 = ((10 * (6 / -132)) + 17) + 5 = ((10 * 0) + 17) + 5 = (0 + 17) + 5 = 17 + 5 = 22
Constraints:
1 <= tokens.length <= 104tokens[i]is either an operator:"+","-","*", or"/", or an integer in the range[-200, 200].
Solution : use stack to solve this problem, if meet +-*/ pop two number from stack, do the opertaion and push back. Mind the order of num1 and num2 in operation.
class Solution {
public int evalRPN(String[] tokens) {
Deque<Integer> stack = new ArrayDeque<>();
for (String str : tokens) {
if (str.equals("+") || str.equals("-") || str.equals("*") || str.equals("/"))
stack.offerFirst(operate(stack.pollFirst(), stack.pollFirst(), str));
else
stack.offerFirst(Integer.valueOf(str));
}
return stack.pollFirst();
}
private Integer operate(Integer str1, Integer str2, String ope) {
if (ope.equals("+")) return str2 + str1;
if (ope.equals("-")) return str2 - str1;
if (ope.equals("*")) return str2 * str1;
if (ope.equals("/")) return str2 / str1;
return 0;
}
}
TC : O(n) traverse all string
SC : O(n) stack space
735. Asteroid Collision
We are given an array asteroids of integers representing asteroids in a row.
For each asteroid, the absolute value represents its size, and the sign represents its direction (positive meaning right, negative meaning left). Each asteroid moves at the same speed.
Find out the state of the asteroids after all collisions. If two asteroids meet, the smaller one will explode. If both are the same size, both will explode. Two asteroids moving in the same direction will never meet.
Example 1:
Input: asteroids = [5,10,-5] Output: [5,10] Explanation: The 10 and -5 collide resulting in 10. The 5 and 10 never collide.
Example 2:
Input: asteroids = [8,-8] Output: [] Explanation: The 8 and -8 collide exploding each other.
Example 3:
Input: asteroids = [10,2,-5] Output: [10] Explanation: The 2 and -5 collide resulting in -5. The 10 and -5 collide resulting in 10.
Constraints:
2 <= asteroids.length <= 104-1000 <= asteroids[i] <= 1000asteroids[i] != 0
Solution : stack, if we need compare many times with the previous number, we can use stack in this situation.
class Solution {
public int[] asteroidCollision(int[] asteroids) {
Deque<Integer> stack = new ArrayDeque<Integer>();
for (int aster : asteroids) {
boolean alive = true;
while (alive && aster < 0 && !stack.isEmpty() && stack.peek() > 0) {
alive = stack.peek() < -aster; // aster 是否存在
if (stack.peek() <= -aster) { // 栈顶行星爆炸
stack.pop();
}
}
if (alive) {
stack.push(aster);
}
}
int size = stack.size();
int[] ans = new int[size];
for (int i = size - 1; i >= 0; i--) {
ans[i] = stack.pop();
}
return ans;
}
}
TC : O(n) traverse time
SC : O(n) stack space
739. Daily Temperatures
Given an array of integers temperatures represents the daily temperatures, return an array answer such that answer[i] is the number of days you have to wait after the ith day to get a warmer temperature. If there is no future day for which this is possible, keep answer[i] == 0 instead.
Example 1:
Input: temperatures = [73,74,75,71,69,72,76,73] Output: [1,1,4,2,1,1,0,0]
Example 2:
Input: temperatures = [30,40,50,60] Output: [1,1,1,0]
Example 3:
Input: temperatures = [30,60,90] Output: [1,1,0]
Constraints:
1 <= temperatures.length <= 10530 <= temperatures[i] <= 100
Solution : monotonic stack
//Personal solution:
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
Deque<Pair<Integer, Integer>> stack = new ArrayDeque<>();
int[] res = new int[temperatures.length];
for (int i = temperatures.length - 1; i >= 0; i--) {
int sum = 1;
while (!stack.isEmpty() && temperatures[stack.peekLast().getKey()] <= temperatures[i]) {
Pair<Integer, Integer> top = stack.pollLast();
res[top.getKey()] = top.getValue();
sum += top.getValue();
}
Pair<Integer, Integer> cur = new Pair<>(i, sum);
stack.offerLast(cur);
}
while (!stack.isEmpty()) {
Pair<Integer, Integer> top = stack.pollLast();
res[top.getKey()] = top.getValue();
}
// from right to left set 0 to no warmer day
int max = Integer.MIN_VALUE;
int j = temperatures.length - 1;
while (j >= 0) {
if (temperatures[j] >= max) {
res[j] = 0;
max = Math.max(temperatures[j], max);
};
j--;
}
return res;
}
}
TC : O(n)
SC : O(n)
Solution2 : monotonic stack (OPT way)
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
int length = temperatures.length;
int[] ans = new int[length];
Deque<Integer> stack = new LinkedList<Integer>();
for (int i = 0; i < length; i++) {
int temperature = temperatures[i];
while (!stack.isEmpty() && temperature > temperatures[stack.peek()]) {
int prevIndex = stack.pop();
ans[prevIndex] = i - prevIndex;
}
stack.push(i);
}
return ans;
}
}
TC : O(n)
SC : O(n)
84. Largest Rectangle in Histogram
Given an array of integers heights representing the histogram's bar height where the width of each bar is 1, return the area of the largest rectangle in the histogram.
Example 1:
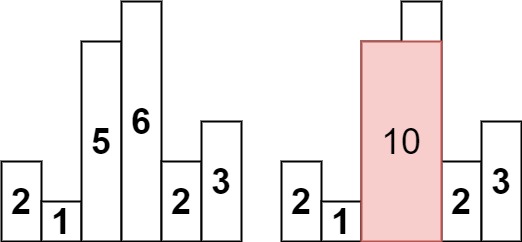
Input: heights = [2,1,5,6,2,3] Output: 10 Explanation: The above is a histogram where width of each bar is 1. The largest rectangle is shown in the red area, which has an area = 10 units.
Example 2:
Input: heights = [2,4] Output: 4
Constraints:
1 <= heights.length <= 1050 <= heights[i] <= 104
Solution : monotonic stack
class Solution {
public int largestRectangleArea(int[] heights) {
int[] minLeft = new int[heights.length];
int[] minRight = new int[heights.length];
Deque<Integer> stack = new ArrayDeque<>();
// -1 means it can extend to the border
for (int i = 0; i < heights.length; i++) {
while (!stack.isEmpty() && heights[stack.peekLast()] >= heights[i]) {
stack.pollLast();
}
minLeft[i] = stack.isEmpty() ? -1 : stack.peekLast();
stack.offerLast(i);
}
stack.clear();
for (int i = heights.length - 1; i >= 0; i--) {
while (!stack.isEmpty() && heights[stack.peekLast()] > heights[i]) {
stack.pollLast();
}
minRight[i] = stack.isEmpty() ? heights.length : stack.peekLast();
stack.offerLast(i);
}
//
int globalMax = Integer.MIN_VALUE;
for (int i = 0; i < heights.length; i++) {
int area = (minRight[i] - minLeft[i] - 1) * heights[i];
globalMax = Math.max(globalMax, area);
}
return globalMax;
}
}
TC : O(n)
SC : O(n)
85. Maximal Rectangle
Given a rows x cols binary matrix filled with 0's and 1's, find the largest rectangle containing only 1's and return its area.
Example 1:

Input: matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]] Output: 6 Explanation: The maximal rectangle is shown in the above picture.
Example 2:
Input: matrix = [["0"]] Output: 0
Example 3:
Input: matrix = [["1"]] Output: 1
Constraints:
rows == matrix.lengthcols == matrix[i].length1 <= row, cols <= 200matrix[i][j]is'0'or'1'.
Solution : prefix sum + monotonic stack
class Solution {
public int maximalRectangle(String[] matrix) {
if (matrix == null || matrix.length == 0) return 0;
int[] sum = new int[] {0};
int[][] mt = new int[matrix.length][matrix[0].length()];
// initialize the prefix sum matrix
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[0].length(); j++) {
if (i == 0 || mt[i - 1][j] == 0 || matrix[i].charAt(j) == '0') mt[i][j] = matrix[i].charAt(j) - '0';
else {
mt[i][j] = mt[i - 1][j] + matrix[i].charAt(j) - '0';
}
}
}
for (int i = 0; i < matrix.length; i++) {
// it is the same with the problem 84
largestRectangleArea(mt[i], sum);
}
return sum[0];
}
private void largestRectangleArea(int[] heights, int[] sum) {
int[] minLeft = new int[heights.length];
int[] minRight = new int[heights.length];
Deque<Integer> stack = new ArrayDeque<>();
for (int i = 0; i < heights.length; i++) {
while (!stack.isEmpty() && heights[stack.peekLast()] >= heights[i]) {
stack.pollLast();
}
minLeft[i] = stack.isEmpty() ? -1 : stack.peekLast();
stack.offerLast(i);
}
stack.clear();
for (int i = heights.length - 1; i >= 0; i--) {
while (!stack.isEmpty() && heights[stack.peekLast()] > heights[i]) {
stack.pollLast();
}
minRight[i] = stack.isEmpty() ? heights.length : stack.peekLast();
stack.offerLast(i);
}
//
for (int i = 0; i < heights.length; i++) {
int area = (minRight[i] - minLeft[i] - 1) * heights[i];
sum[0] = Math.max(sum[0], area);
}
return;
}
}
TC : O(mn) m n is the shape of the matrix
SC : O(mn)
919. Complete Binary Tree Inserter
A complete binary tree is a binary tree in which every level, except possibly the last, is completely filled, and all nodes are as far left as possible.
Design an algorithm to insert a new node to a complete binary tree keeping it complete after the insertion.
Implement the CBTInserter class:
CBTInserter(TreeNode root)Initializes the data structure with therootof the complete binary tree.int insert(int v)Inserts aTreeNodeinto the tree with valueNode.val == valso that the tree remains complete, and returns the value of the parent of the insertedTreeNode.TreeNode get_root()Returns the root node of the tree.
Example 1:
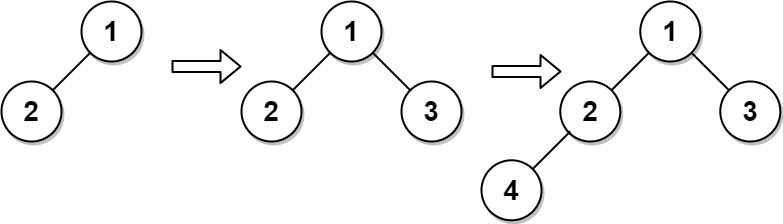
Input ["CBTInserter", "insert", "insert", "get_root"] [[[1, 2]], [3], [4], []] Output [null, 1, 2, [1, 2, 3, 4]] Explanation CBTInserter cBTInserter = new CBTInserter([1, 2]); cBTInserter.insert(3); // return 1 cBTInserter.insert(4); // return 2 cBTInserter.get_root(); // return [1, 2, 3, 4]
Constraints:
- The number of nodes in the tree will be in the range
[1, 1000]. 0 <= Node.val <= 5000rootis a complete binary tree.0 <= val <= 5000- At most
104calls will be made toinsertandget_root.
Solution : Use queue to do a level order BFS
class CBTInserter {
TreeNode root;
Deque<TreeNode> queue;
public CBTInserter(TreeNode root) {
queue = new ArrayDeque<>();
this.root = root;
// do a level order BFS, the condition we add to queue is not both left and right are exists.
Deque<TreeNode> queueLevel = new ArrayDeque<>();
queueLevel.offerLast(root);
while (!queueLevel.isEmpty()) {
TreeNode cur = queueLevel.pollFirst();
// store
if (!(cur.left != null && cur.right != null)) {
queue.offerLast(cur);
}
if (cur.left != null) {
queueLevel.offerLast(cur.left);
}
if (cur.right != null) {
queueLevel.offerLast(cur.right);
}
}
}
// all nodes in queue is
public int insert(int val) {
TreeNode cur = queue.peekFirst();
TreeNode newNode = new TreeNode(val);
if (cur.left == null) {
cur.left = newNode;
queue.offerLast(newNode);
} else {
cur.right = newNode;
queue.offerLast(newNode);
queue.pollFirst();
}
return cur.val;
}
public TreeNode get_root() {
return this.root;
}
}
TC : O(n) initilize and O(1) insert and get
SC : O(n + insert times)
199. Binary Tree Right Side View
Given the root of a binary tree, imagine yourself standing on the right side of it, return the values of the nodes you can see ordered from top to bottom.
Example 1:

Input: root = [1,2,3,null,5,null,4] Output: [1,3,4]
Example 2:
Input: root = [1,null,3] Output: [1,3]
Example 3:
Input: root = [] Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 100]. -100 <= Node.val <= 100
Solution : BFS, Queue always comes with BFS, in binary tree, it always combines with the level order traverse.
class Solution {
public List<Integer> rightSideView(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
Deque<TreeNode> queue = new ArrayDeque<>();
queue.offerLast(root);
while (!queue.isEmpty()) {
res.add(queue.peekFirst().val);
int size = queue.size();
while (size -- > 0) {
TreeNode cur = queue.pollFirst();
// root, right, left
if (cur.right != null) {
queue.offerLast(cur.right);
}
if (cur.left != null) {
queue.offerLast(cur.left);
}
}
}
return res;
}
}
TC : O(n) n is the nodes of the tree
SC : O(n)
Solution2 : DFS, DFS is another solution here
class Solution {
List<Integer> res = new ArrayList<>();
public List<Integer> rightSideView(TreeNode root) {
dfs(root, 0);
return res;
}
private void dfs(TreeNode root, int depth) {
if (root == null) {
return;
}
// root, right, left
if (depth == res.size()) { // res == depth means this is the rightest node in this level.
res.add(root.val);
}
depth++;
dfs(root.right, depth);
dfs(root.left, depth);
}
}
TC : O(n) n is the nodes of the tree
SC : O(n) is call stack
297. Serialize and Deserialize Binary Tree
Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.
Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.
Clarification: The input/output format is the same as how LeetCode serializes a binary tree. You do not necessarily need to follow this format, so please be creative and come up with different approaches yourself.
Example 1:
Input: root = [1,2,3,null,null,4,5] Output: [1,2,3,null,null,4,5]
Example 2:
Input: root = [] Output: []
Constraints:
- The number of nodes in the tree is in the range
[0, 104]. -1000 <= Node.val <= 1000
Solution : We could use BFS or DFS
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
if (root == null) {
return "X,";
}
String left = serialize(root.left);
String right = serialize(root.right);
return root.val + "," + left + right;
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
String[] nodes = data.split(",");
Queue<String> queue = new ArrayDeque<>(Arrays.asList(nodes));
return buildTree(queue);
}
// like build or delete nodes, these changing tree structer problem, we could do it recursively
public TreeNode buildTree(Queue<String> queue) {
String value = queue.poll();
if (value.equals("X")) {
return null;
}
TreeNode node = new TreeNode(Integer.parseInt(value));
node.left = buildTree(queue);
node.right = buildTree(queue);
return node;
}
}
TC : O(n)
SC : O(n)
Here is BFS solution
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
if (root == null) {
return "";
}
StringBuilder sb = new StringBuilder();
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node == null) {
sb.append("X,");
} else {
sb.append(node.val + ",");
queue.offer(node.left);
queue.offer(node.right);
}
}
return sb.toString();
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
if (data == "") {
return null;
}
Queue<String> nodes = new ArrayDeque<>(Arrays.asList(data.split(",")));
TreeNode root = new TreeNode(Integer.parseInt(nodes.poll()));
Queue<TreeNode> queue = new ArrayDeque<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
String left = nodes.poll();
String right = nodes.poll();
if (!left.equals("X")) {
node.left = new TreeNode(Integer.parseInt(left));
queue.add(node.left);
}
if (!right.equals("X")) {
node.right = new TreeNode(Integer.parseInt(right));
queue.add(node.right);
}
}
return root;
}
}
TC : O(n)
SC : O(n)